8 Padrões Pontuais II
8.1 Alguns usos em Epidemiologia Espacial
A partir de processos pontuais é possível se realizar análises tais quais:
- Estimar a variação do risco relativo no espaço
- Estudos Caso-Controle espaciais
- Regressões logísticas lineares e não lineares (GAM) no espaço
- Análises de processos pontuais marcados (marked point processes)
8.2 Exemplo com os dados de dengue em Dourados/MS
Nesta aula serão utilizados os dados da monografia de Isis Rodrigues Reitman, apresentada ao Curso de Geografia da Faculdade de Ciências Humanas da Universidade Federal da Grande Douradosos/MS, em março de 2013. O título da monografia é “DISTRIBUIÇÃO ESPACIAL DOS CASOS DE DENGUE NO PERÍMETRO URBANO DE DOURADOS-MS E SUA RELAÇÃO COM OS FATORES SOCIOAMBIENTAIS E POLÍTICOS”
Carregando pacotes:
Lendo a tabela da população por setor censitário e baixando os shapefiles do contorno e dos setores censitários de Dourados/MS:
local <- "https://raw.githubusercontent.com/ogcruz/dados_eco_2023/main/dados/"
pop2010 <- read_csv(paste0(local, "pop2010.csv"))
tmpdir <- tempdir()
download.file(paste0(local, "setores_dourados.zip"),
destfile = paste0(tmpdir, "/dourados.zip"))
unzip(zipfile = paste0(tmpdir, "/dourados.zip"), exdir = tmpdir)
dir(tmpdir)
setor <- read_sf(paste0(tmpdir, "/Setor_UTM_SIRGAS.shp"),
crs = 31981)
contorno <- read_sf(paste0(tmpdir, "/contorno.shp"),
crs = 31981)
popsetor <- setor %>%
mutate(idsetor = as.numeric(CD_GEOCODI)) %>%
left_join(pop2010, by = "idsetor")Lendo os casos de dengue georreferenciados em Dourados/MS:
casos <- read_csv(paste0(local, "dengue_dourados.csv"))
casos.pt <- casos %>%
st_as_sf(coords = c("X", "Y"), crs = 31981)Plotando os casos de dengue segundo o sexo:
Usando a ggplot() para fazer um gráfico do contorno e dos casos:
Formatando os pontos que representam os casos de dengue na classe ppp (point pattern):
cont.w <- as.owin(contorno)
dengue.ppp <- ppp(x = casos$X, y = casos$Y, window = cont.w)
plot(dengue.ppp, pch = 16, cex = 0.5, cols = "red",
main = "casos dengue")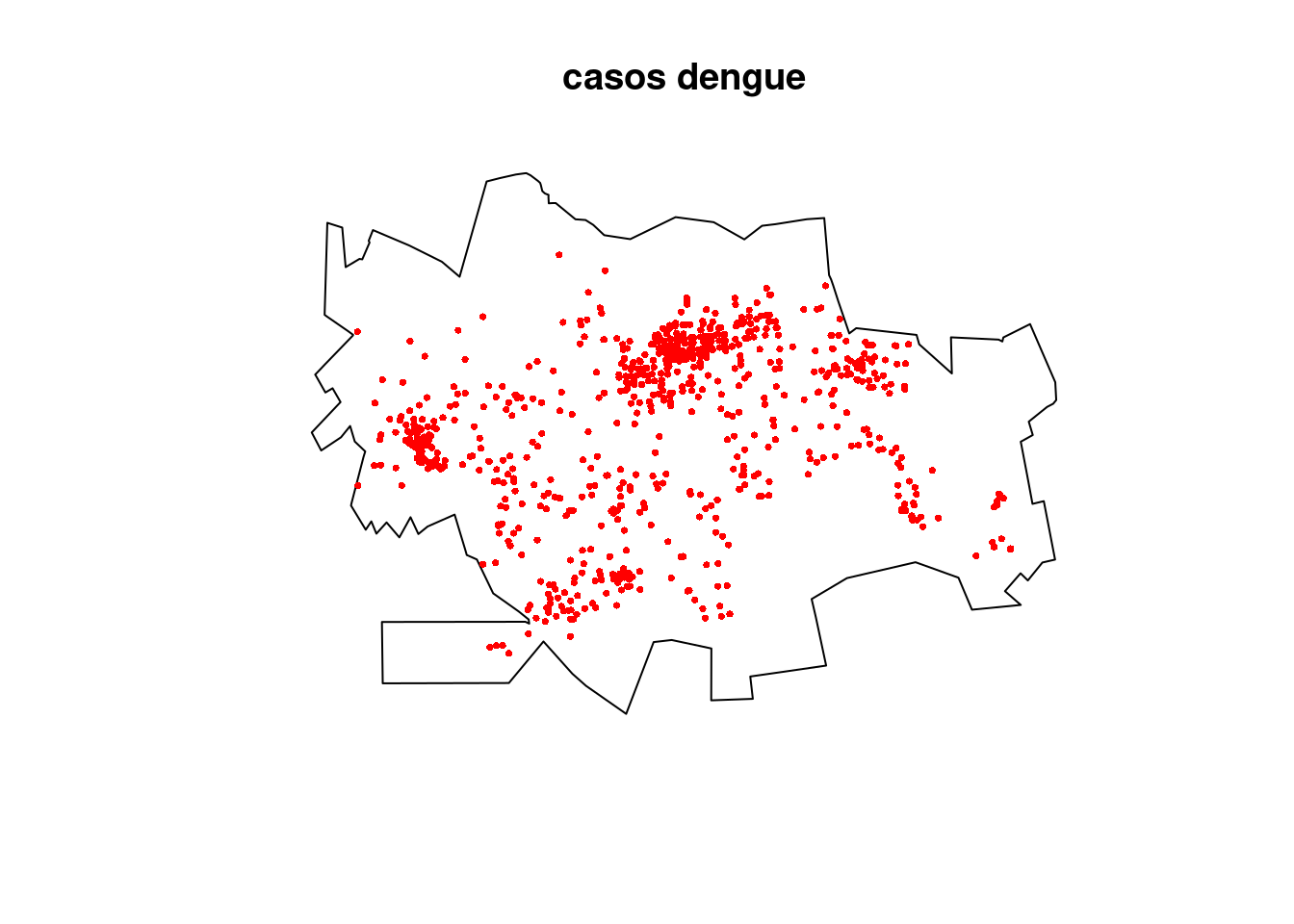
Como vimos anteriormente podemos usar a técnica de quadrats para termos uma ideia da distribuição dos casos de dengue em Dourados/MS. Vamos usar nesse caso um grade de 5x5 (25 quadrados) , no entando pode-se ajustar esse valor e não é necessário que a grade seja simétrica.
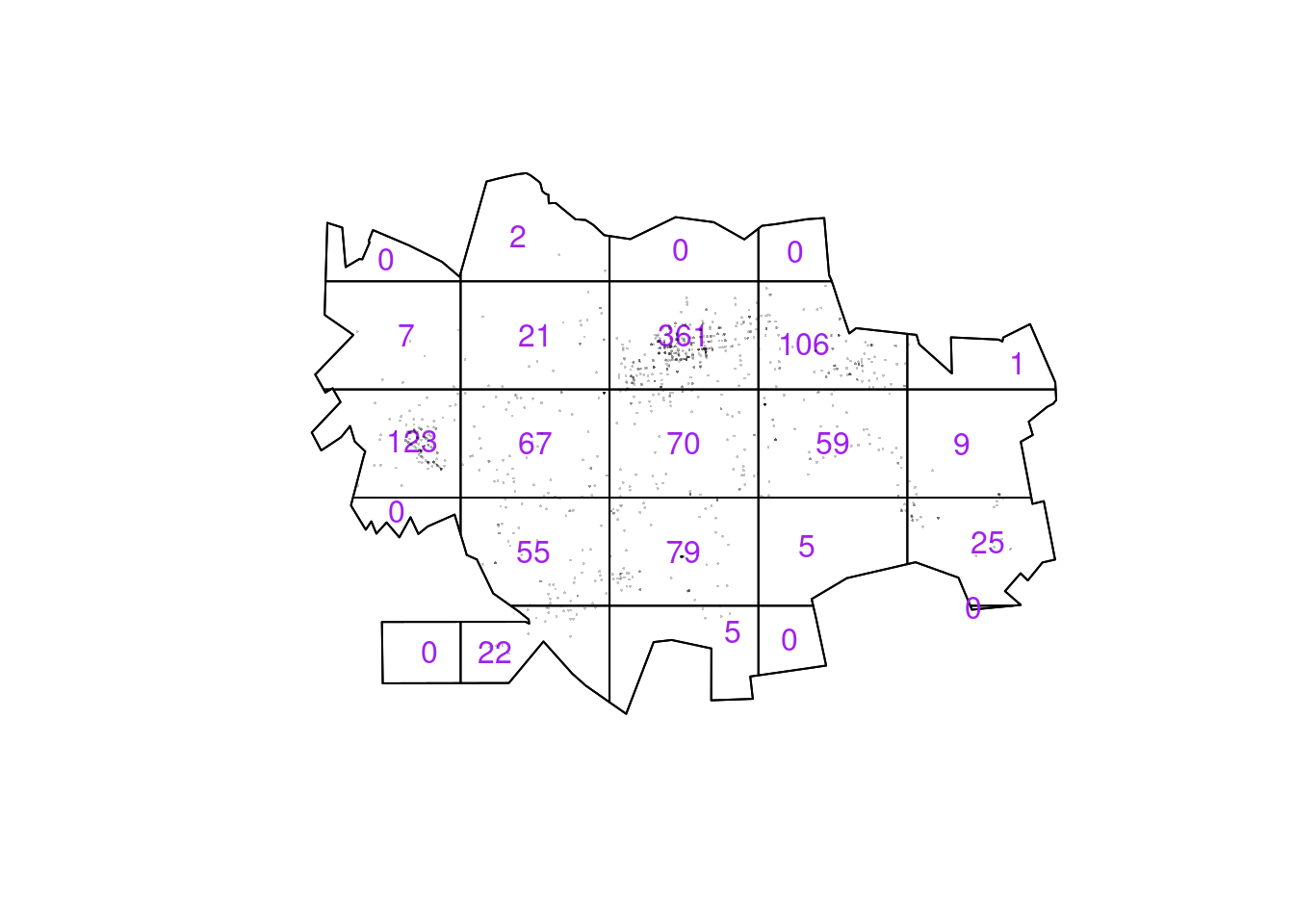
##
## Conditional Monte Carlo test of CSR using quadrat counts
## Test statistic: Pearson X2 statistic
##
## data:
## X2 = 1927, p-value = 1e-04
## alternative hypothesis: clustered
##
## Quadrats: 24 tiles (irregular windows)Uma vez que temos o objeto em formato ppp, visualizamos pelo método dos quadrats podemos verificar a melhor largura de banda sugerida por vários métodos disponíveis pela biblioteca spatstat para os casos de Dengue em Dourados/MS.
| Nome | Comando R | Resultado |
|---|---|---|
| Diggle | bw.diggle(dengue.ppp) | 14.1335 |
| Cronie and van Lieshout’s (CvL) | bw.CvL(dengue.ppp) | 1630.7311 |
| Scoot | bw.scott(dengue.ppp) | 771.6202, 467.906 |
| likelihood cross-validation | bw.ppl(dengue.ppp) | 178.0477 |
Existem ainda outros métodos para determinar automaticamente a largura de banda. É possível usá-los para ajudar a escolher o melhor valor, mas é preciso verificar se essa largura de banda apresenta plausibilidade dentro do contexto do estudo.
Fazendo o mapa de kernel dos casos de dengue segundo várias larguras de banda.
par(mfrow = c(2, 2), mar = c(1, 1, 1, 1))
plot(density(dengue.ppp, 250, diggle = TRUE), main = "kernel 250 m",
col = terrain.colors(64))
plot(density(dengue.ppp, 500, diggle = TRUE), main = "kernel 500 m",
col = terrain.colors(64))
plot(density(dengue.ppp, 750, diggle = TRUE), main = "kernel 750 m",
col = terrain.colors(64))
plot(density(dengue.ppp, 1000, diggle = TRUE), main = "kernel 1000 m",
col = terrain.colors(64))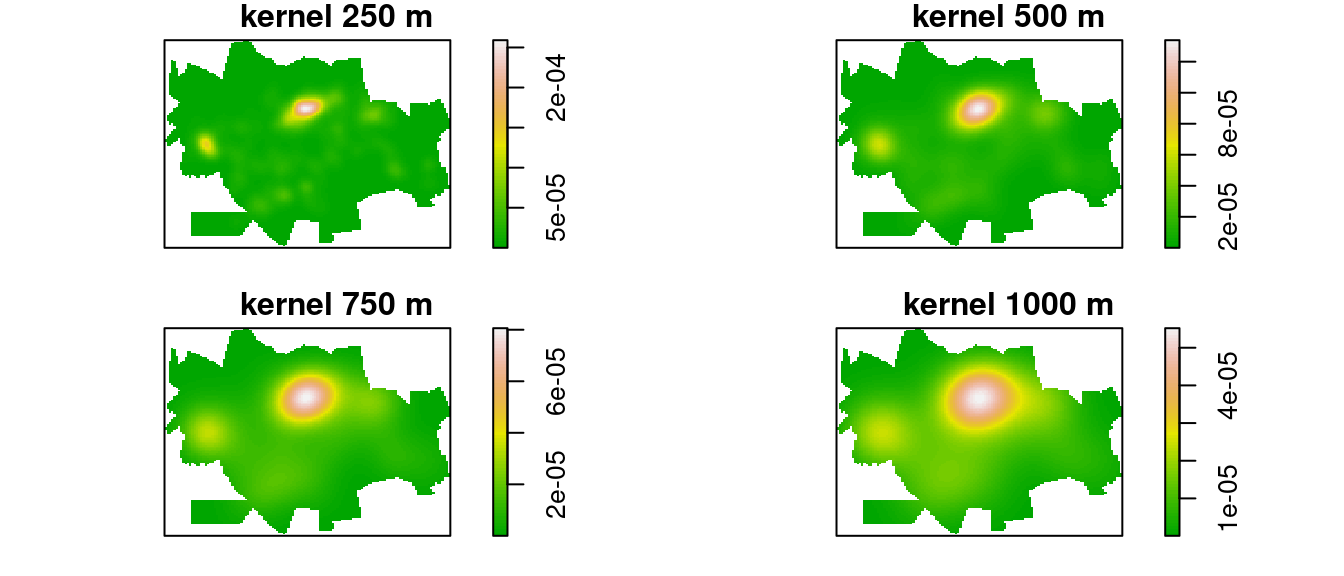
Fazendo o kernel segundo sexo, criando padrões para cada sexo e em seguida gerando um kernel para cada categoria.
masc <- casos %>%
filter(CS_SEXO == "M")
masc.ppp <- ppp(x = masc$X, y = masc$Y, window = cont.w)
fem <- casos %>%
filter(CS_SEXO == "F")
fem.ppp <- ppp(x = fem$X, y = fem$Y, window = cont.w)
D.masc <- density(masc.ppp, 750, diggle = TRUE)
D.fem <- density(fem.ppp, 750, diggle = TRUE)
par(mfrow = c(1, 2), mar = c(1, 0, 1, 2))
plot(D.masc, main = "kernel Homens 750 m")
plot(D.fem, main = "kernel Mulheres 750 m")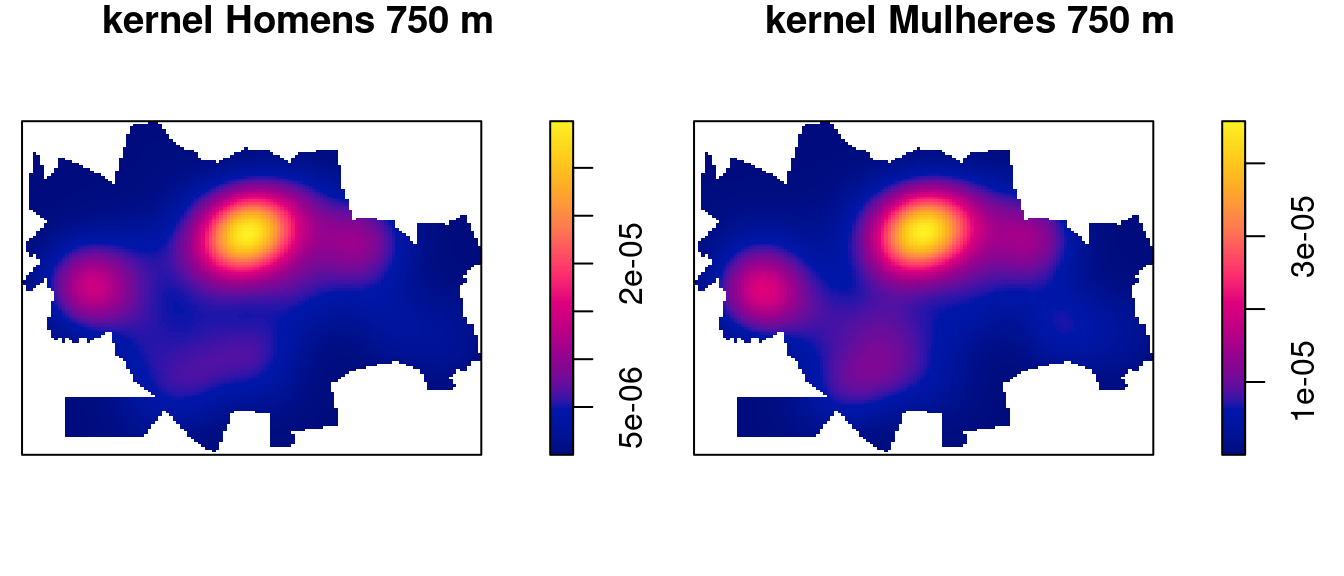
Fazendo a razão de kernel entre os sexos:
D.res <- D.masc/D.fem
plot(D.res, main = "Razão de Kernel H/M", box = FALSE)
plot(contorno[1], add = T, col = NA)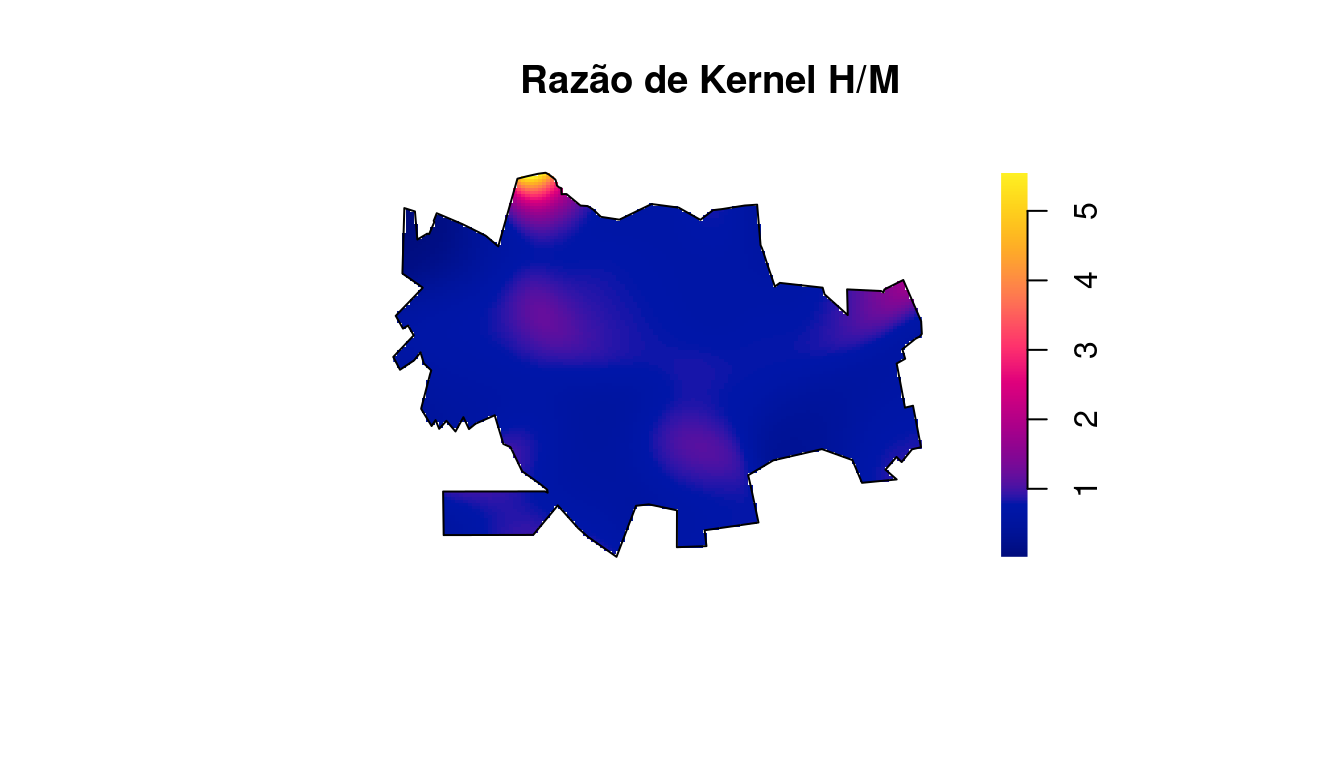
Podemos também fazer a proporção de homens, dividindo o kernel de homens pela soma do kernel de homens + kernel das mulheres. Vamos adicionar informações de contorno para visualizar melhor as regiões onde tem proporções iguais!
cores <- heat.colors(16, rev = TRUE)
D.res <- D.masc/(D.masc + D.fem)
plot(D.res, main = "Proporção de Homens", addcontour = TRUE,
col = cores, box = FALSE)
plot(contorno[1], add = T, col = NA)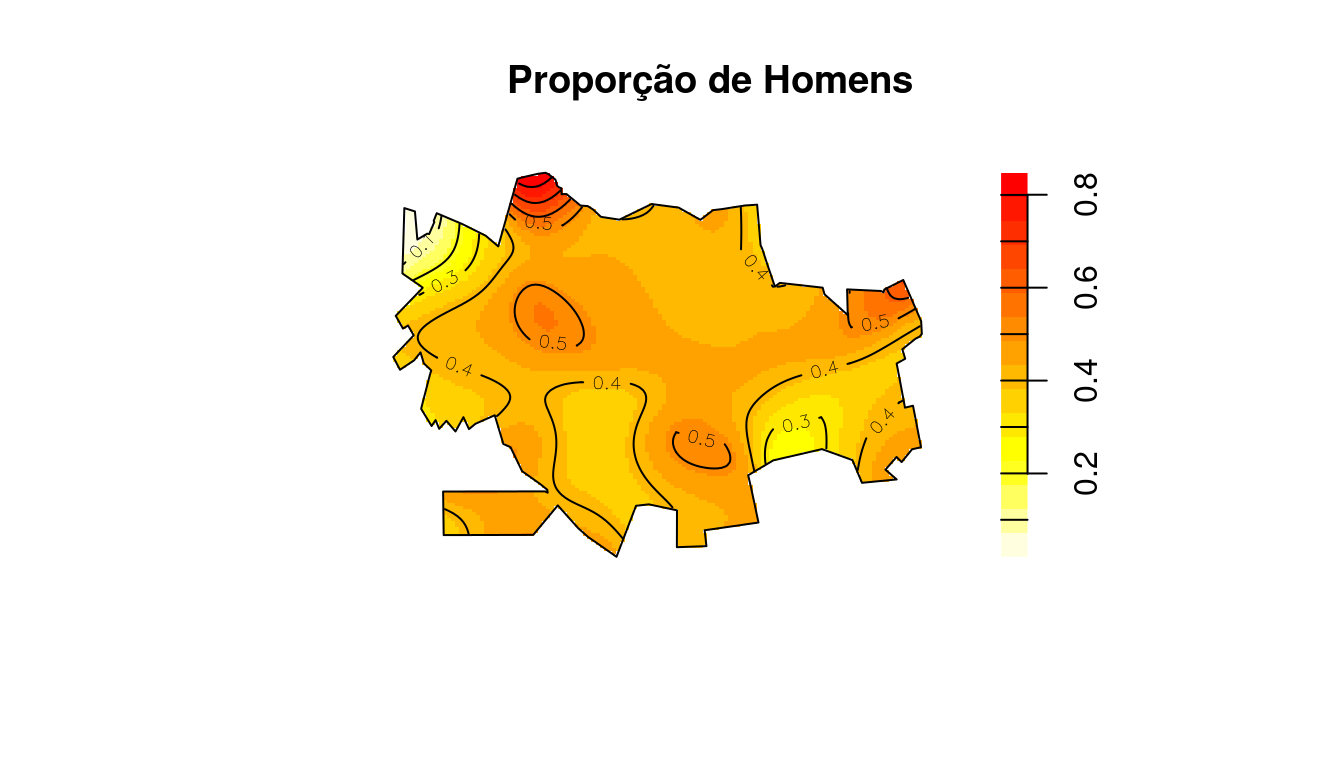
Como podemos observar no kernel acima, não foi detectada variabilidade espacial na razão entre os sexos. Observe o efeito de borda que ocorre no Norte, onde um único indivíduo do sexo masculido é responsável pelo efeito de borda.
Extraindo os centróides dos setores censitários de Dourados/MS.
centros <- st_centroid(st_geometry(popsetor))
centros.tmp <- centros %>%
st_coordinates() %>%
as_tibble()
centros.ppp <- ppp(x = centros.tmp$X, y = centros.tmp$Y,
window = cont.w)
plot(centros.ppp, pch = 19, cex = 0.5, box = FALSE)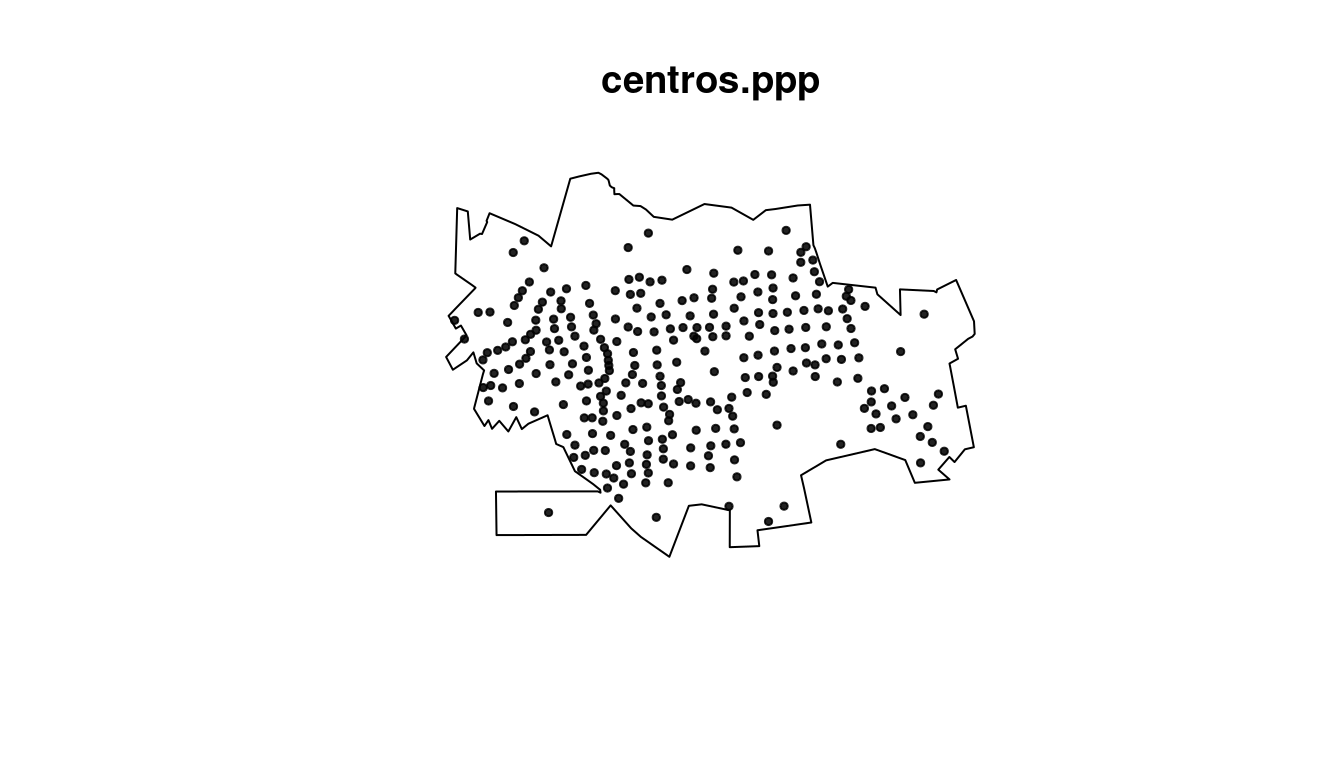
Fazendo o kernel dos pontos dos centróides dos setores censitários de Dourados/MS. Tal distribuição, pode se sugerida como uma proxy da verdadeira distribuição populacional de Dourados/MS.
D.pop <- density(centros.ppp, 500, weights = popsetor$pop,
scalekernel = TRUE)
plot(D.pop, box = FALSE)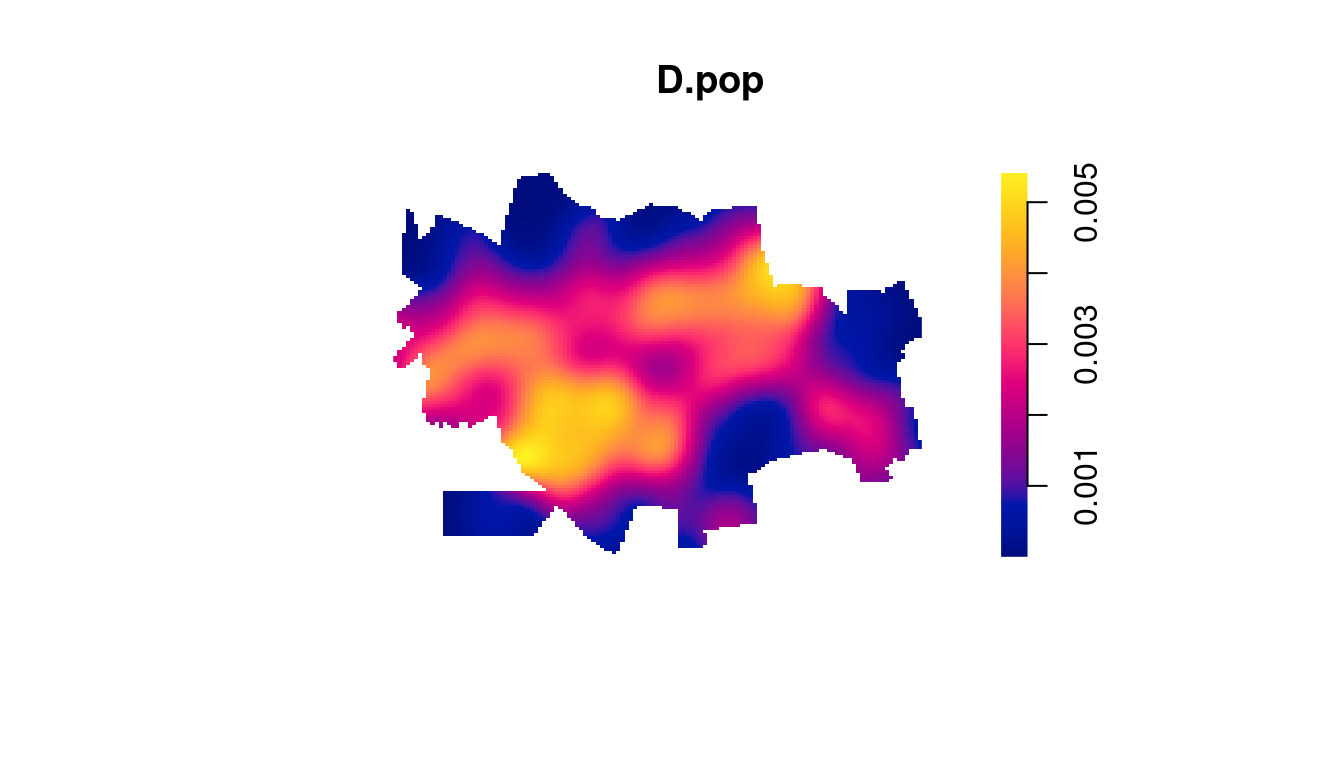
Gerando um kernel de atributo com a população de cada setor censitário. O parâmetro weights nos permite entrar o valor do atributo a ser ponderado. Desta forma é possível gerar um kernel de um valor especificado (atributo).
ker_pop <- density(centros.ppp, 750, weights = popsetor$pop,
scalekernel = TRUE)
plot(ker_pop, box = FALSE)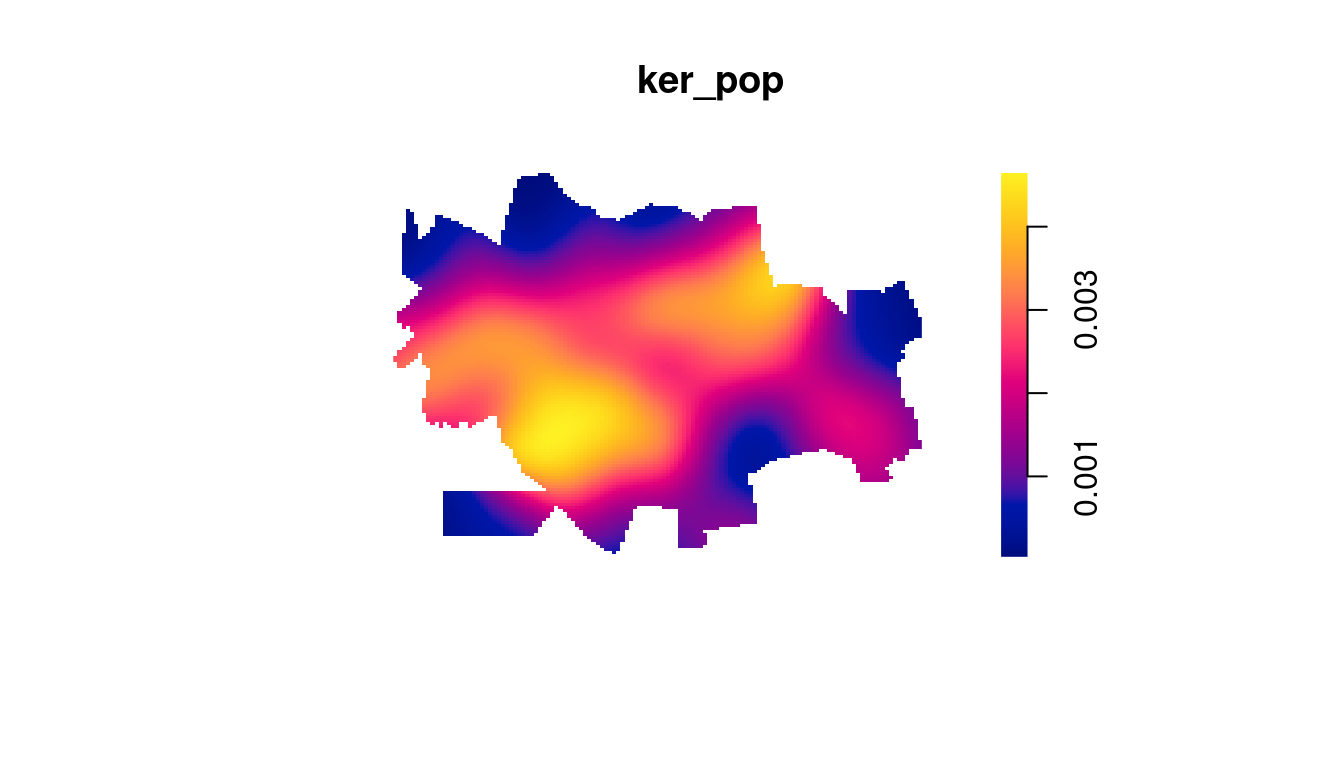
Calculando a taxa média de casos (por 1.000 hab) de dengue do município de Dourados/MS
[1] 5.853
Gerando a razão de kernel (casos/população) x 1000:
kcasos.b750 <- density(dengue.ppp, 750, diggle = TRUE)
razao <- kcasos.b750
razao$v <- (kcasos.b750$v/ker_pop$v) * 1000
plot(razao, main = "Razão de kernel casos/população",
box = FALSE)
contour(razao, add = T, levels = seq(0, 25, by = 5))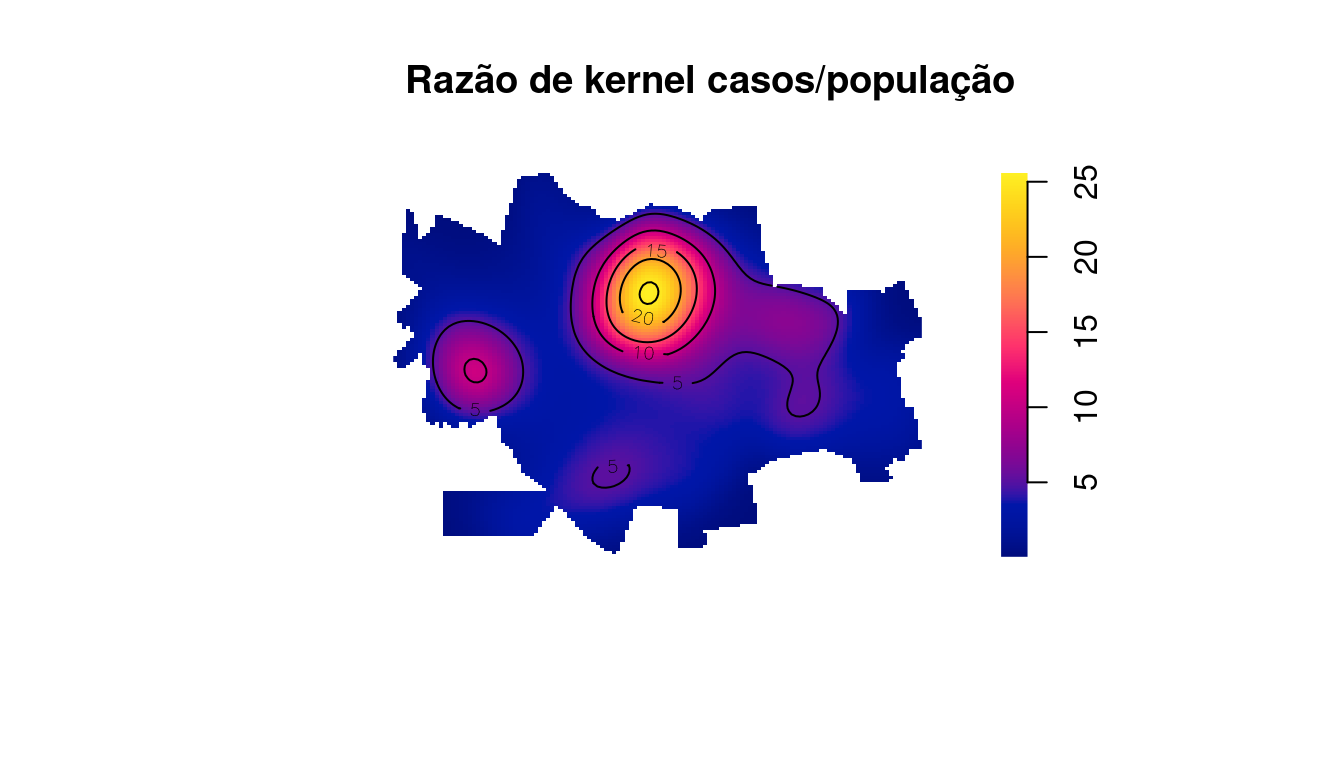
Plotando a distribuição das taxas por dengue estimadas via razão de kernel. É possível verificar que a mediana das razões de kernel é bem próxima a taxa média de casos (por 1.000 hab) em Dourados/MS.
boxplot(as.numeric(razao$v), col = "green", main = "Boxplot da razão de kernel")
abline(h = mean(as.numeric(razao$v), na.rm = T), lty = 3,
col = "red")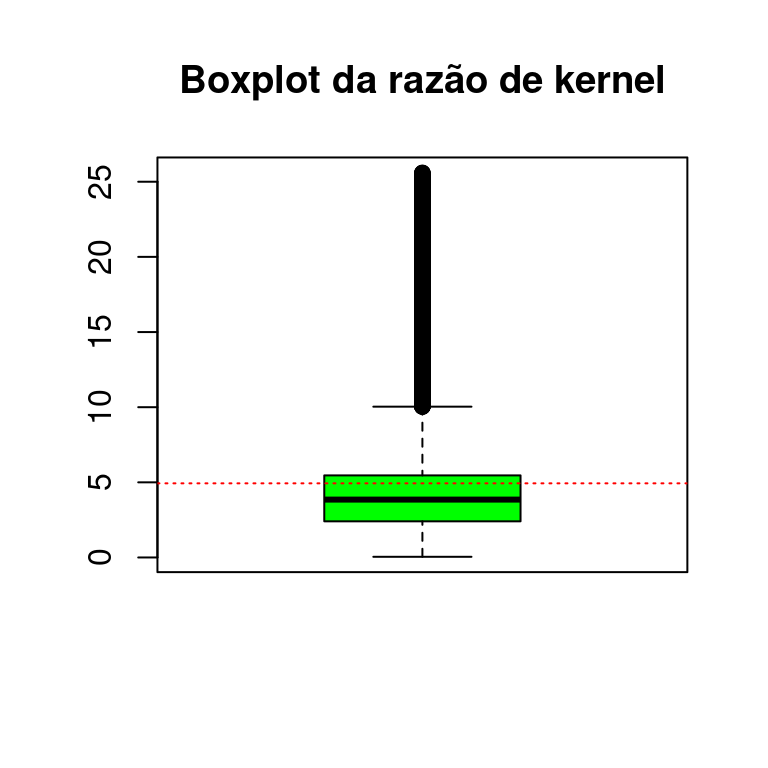
Sobrepondo a malha da população por setores censitários (dados de área) com os pontos de casos de dengue (padrões pontuais)
ggplot(popsetor) + geom_sf(aes(fill = pop)) + geom_sf(data = casos.pt,
color = "white", size = 0.7) + theme_void()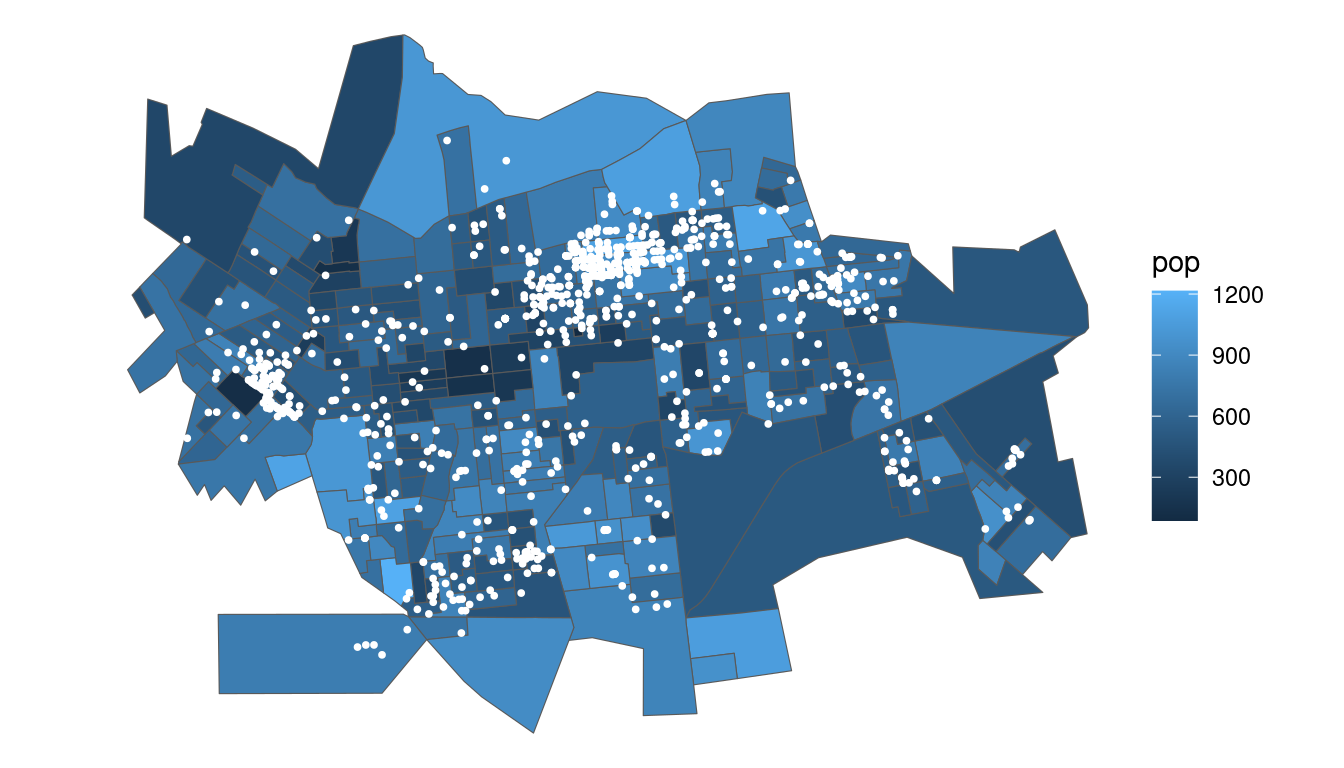
8.3 Modelos Aditivos Generalizados (GAM)
- Um modelo aditivo generalizado (Hastie and Tibishirani, 1990) é um modelo linear generalizado com um preditor linear envolvendo a soma de funções suavizadas das covariáveis + os efeitos fixos das mesmas.
\[\eta = \sum X \beta + f_1(x_{1i}) + f_2(x_{2i}) + \ldots\]
8.4 Modelos Espaciais Generalizados Aditivos
- São modelos aditivos generalizados tendo como um dos preditores o efeito suavizado das componentes espaciais.
\[\eta = \sum X \beta + f_1(x_{1i}) + f_2(x_{2i}) + f_3(latitude_{i}, longitude_{i}) + \ldots\]
Exemplo GAM Dourados - Tipo Caso/Controle
Vamos ajustar um modelo GAM do tipo “caso/controle”, onde casos serão representados pelos casos de dengue confirmados e controles os casos não confirmados.
casos.pt$X <- casos$X
casos.pt$Y <- casos$Y
grade <- expand.grid(X = seq(720900.6, 734155.5, length.out = 150),
Y = seq(7535267.6, 7544897.2, length.out = 100))
suppressMessages(library(mgcv, quietly = TRUE))
mod0 <- gam(CLASSI_FIN == 1 ~ s(X, Y), data = casos.pt,
family = binomial)
Family: binomial
Link function: logit
Formula:
CLASSI_FIN == 1 ~ s(X, Y)
Parametric coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.0069 0.0795 12.7 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Approximate significance of smooth terms:
edf Ref.df Chi.sq p-value
s(X,Y) 21.9 26.2 144 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
R-sq.(adj) = 0.161 Deviance explained = 14.7%
UBRE = 0.085615 Scale est. = 1 n = 1017- Podemos observar que o modelo espacial vazio parace evidenciar que o componente espacial s(X,Y) é significativo, ou seja, existe indícios que o espaço geográfico está influenciando a variável de desfecho.
Agora vamos verificar a saída gráfica original do modelo.
vis.gam(mod0, main = "Modelo Vazio", plot.type = "contour",
color = "terrain", contour.col = "black", lwd = 2)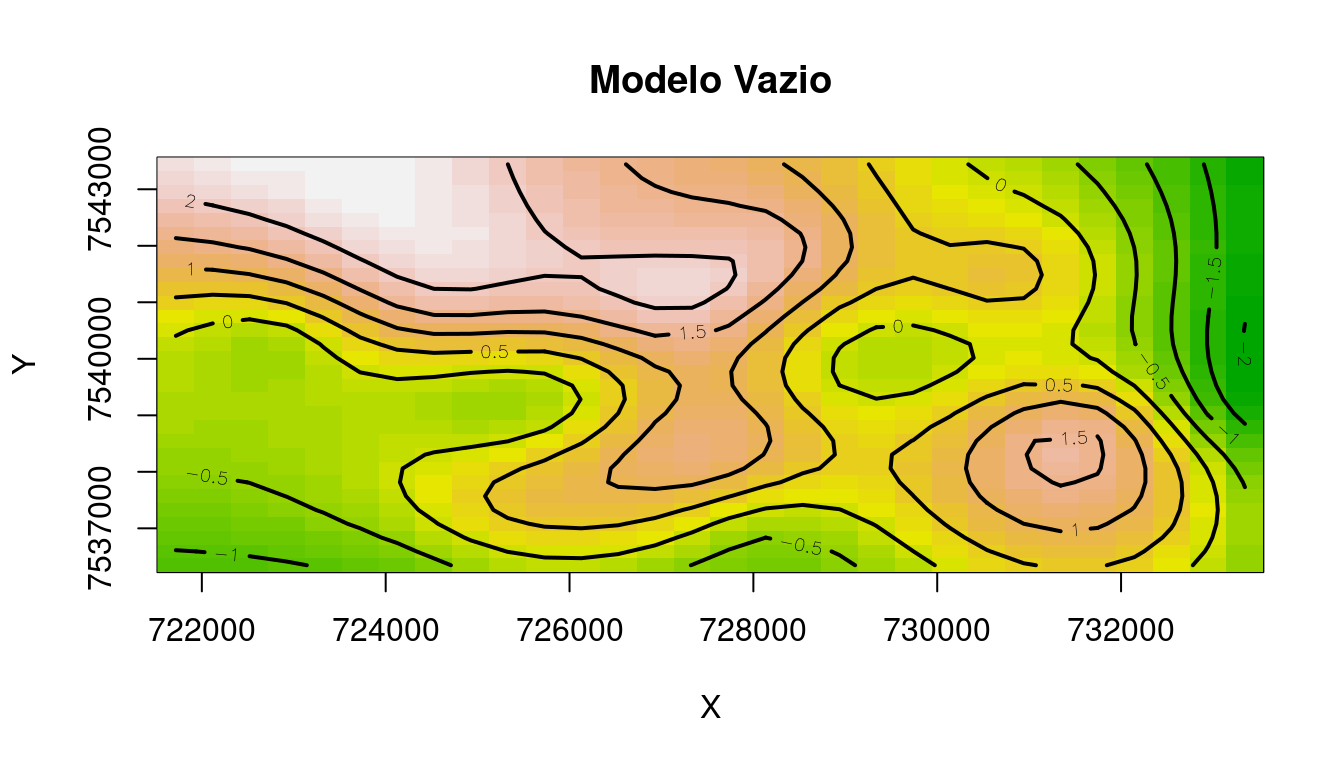
Essa saída não parece ser muito intuitiva, apesar ser possível observarmos as áreas que apresentam ‘pistas’ de haver um risco maior e as áreas que estão mais isentas de casos de dengue.
Vamos agora tentar melhorar tal saída gráfica.
library(splancs)
library(fields)
TAM <- 400
caixa <- st_bbox(contorno)
grade <- expand.grid(x = seq(caixa[1], caixa[3], length.out = TAM),
y = seq(caixa[2], caixa[4], length.out = TAM))
contorno.xy <- as.data.frame(slot(slot(slot(as_Spatial(contorno),
"polygons")[[1]], "Polygons")[[1]], "coords"))
inside <- in.out(as.matrix(contorno.xy), as.matrix(grade))
outside <- list(x = seq(caixa[1], caixa[3], length.out = TAM),
y = seq(caixa[2], caixa[4], length.out = TAM),
z = matrix(rep(0, TAM^2), ncol = TAM))
outside$z[inside] <- NA
x <- outside$x
y <- outside$y
newgam <- data.frame(X = grade[, 1], Y = grade[, 2])
gg.pred <- predict(mod0, newdata = newgam, type = "terms",
terms = "s(X,Y)", se.fit = T)
gg.pred$fit[inside == F] <- NA
gg.pred$se.fit[inside == F] <- NA
z <- exp(matrix(gg.pred$fit, TAM, TAM))
## a very rough estimate of confidence intervals
z.inf <- exp(gg.pred$fit + (1.96 * gg.pred$se.fit))
z.sup <- exp(gg.pred$fit - (1.96 * gg.pred$se.fit))
z.inf <- matrix(z.inf, TAM, TAM)
z.sup <- matrix(z.sup, TAM, TAM)
cores <- c("#053061", "#2166ac", "#4393c3", "#92c5de",
"#d1e5f0", "#f7f7f7", "#fddbc7", "#f4a582", "#d6604d",
"#b2182b", "#67001f")
invisible(split.screen(rbind(c(0, 0.8, 0, 1), c(0.8,
1, 0, 1))))
screen(1)
image(x, y, z, zlim = range(z, na.rm = T), col = cores,
asp = 1, xlab = "", ylab = "", main = "", axes = F)
# points(den$x_coord, den$y_coord, pch=19,
# col='blue', cex=0.1)
contour(x, y, z.inf, nlevels = 1, add = T, col = "blue",
lwd = 2, levels = 1, cex = 0.1, labels = "<1")
contour(x, y, z.sup, nlevels = 1, add = T, col = "red",
lwd = 2, levels = 1, cex = 0.1, labels = ">1")
splancs::polymap(contorno.xy, add = T, lwd = 2)
screen(2) # The legend
# range(z, na.rm=T) # to make a pretty legend
# ticks <- seq(0,0.5,by=0.2)
ticks <- quantile(na.omit(as.vector(z)), prob = seq(0,
1, by = 1/3))
ticks <- seq(0, 5, by = 0.5)
image.plot(zlim = range(z, na.rm = T), col = cores,
axis.args = list(at = ticks, labels = ticks), legend.only = TRUE,
smallplot = c(0.1, 0.25, 0.15, 0.85), legend.width = 3,
legend.shrink = 0.8, horizontal = F)
title("Modelo Vazio")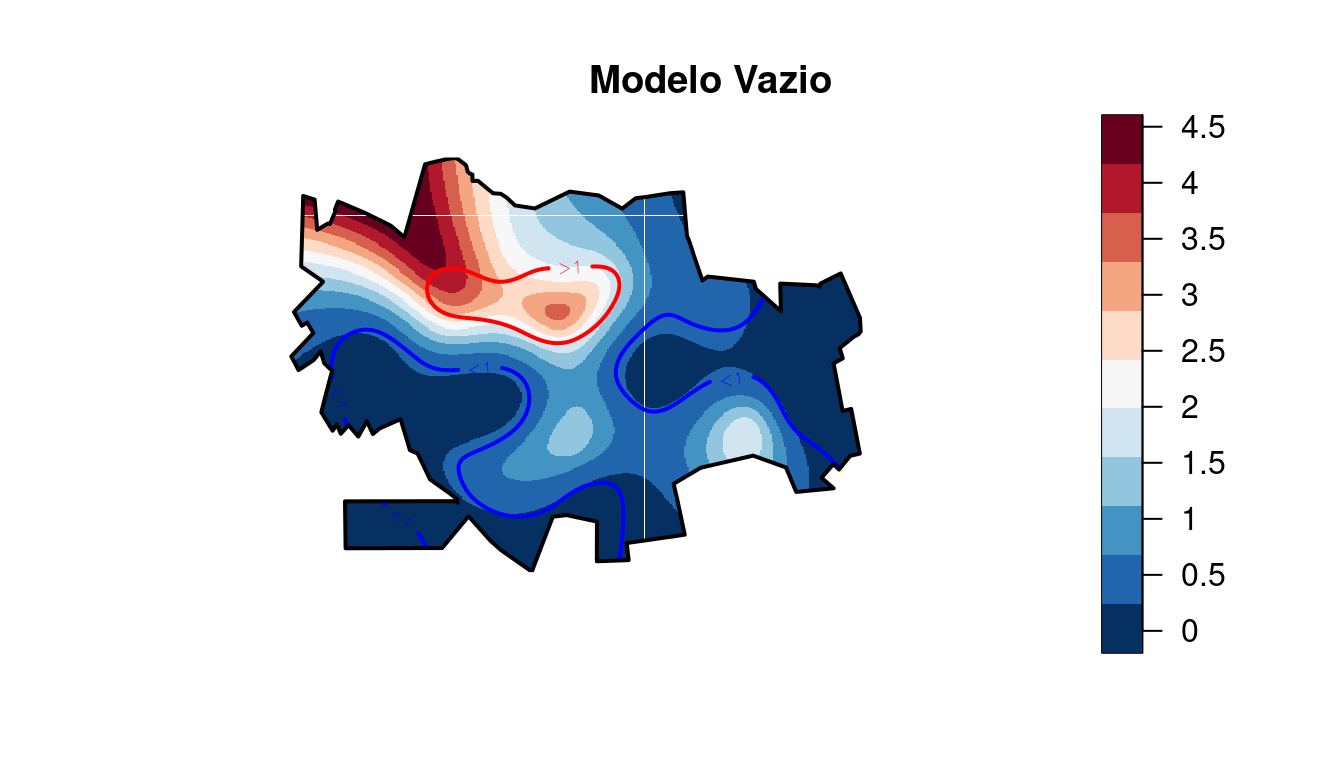
Podemos também inspecionar a superfície do erro padrão do modelo.
z <- matrix(gg.pred$se.fit, TAM, TAM)
invisible(split.screen(rbind(c(0, 0.8, 0, 1), c(0.8,
1, 0, 1))))
screen(1)
image(x, y, z, zlim = range(z, na.rm = T), col = cores,
asp = 1, xlab = "", ylab = "", main = "", axes = F)
splancs::polymap(contorno.xy, add = T, lwd = 2)
screen(2) # The legend
# range(z, na.rm=T) # to make a pretty legend
# ticks <- seq(0,0.5,by=0.2)
ticks <- quantile(na.omit(as.vector(z)), prob = seq(0,
1, by = 1/3))
ticks <- seq(0, 10, by = 1)
image.plot(zlim = range(z, na.rm = T), col = cores,
axis.args = list(at = ticks, labels = ticks), legend.only = TRUE,
smallplot = c(0.1, 0.25, 0.15, 0.85), legend.width = 3,
legend.shrink = 0.8, horizontal = F)
title("Erro Padrão - Modelo Vazio")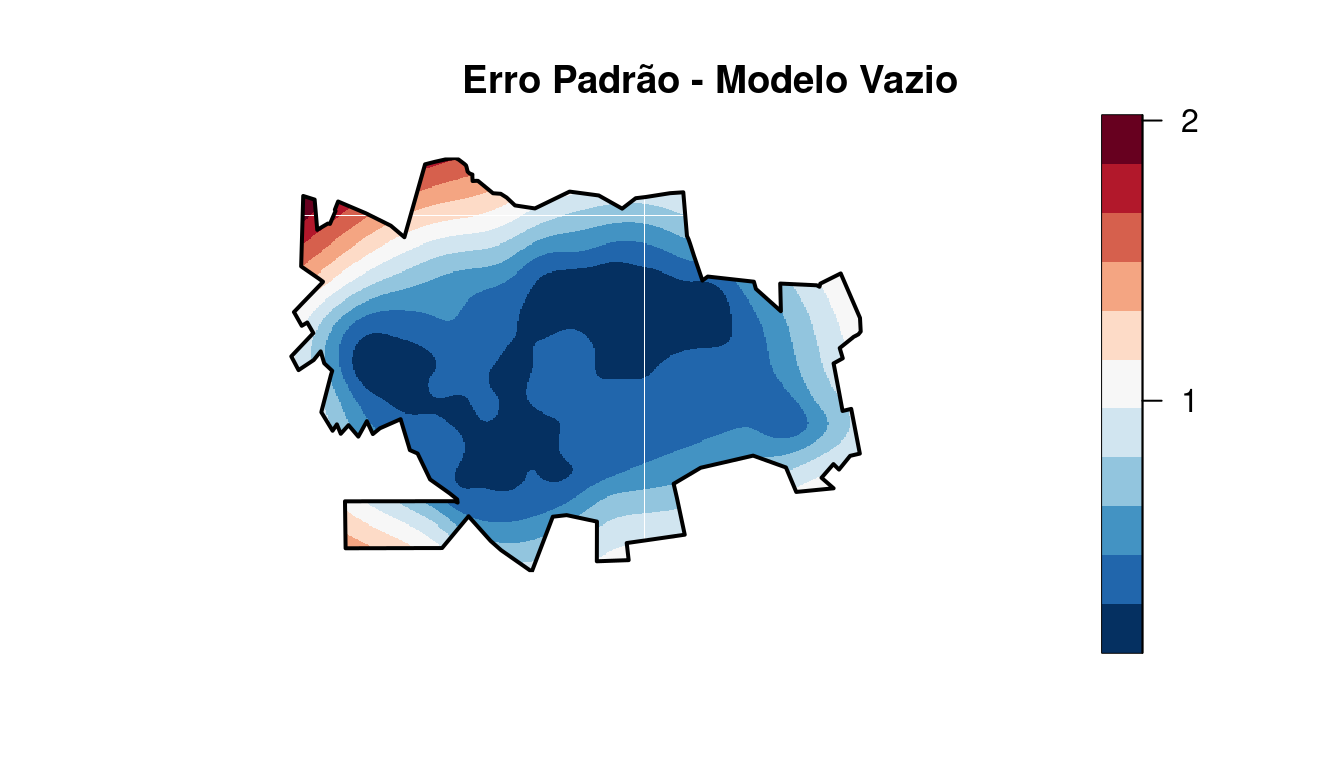
Note que no centro, onde existe a maior quantidade de pontos, o erro e bem menor que nas áreas onde existem menos pontos e nas bordas !
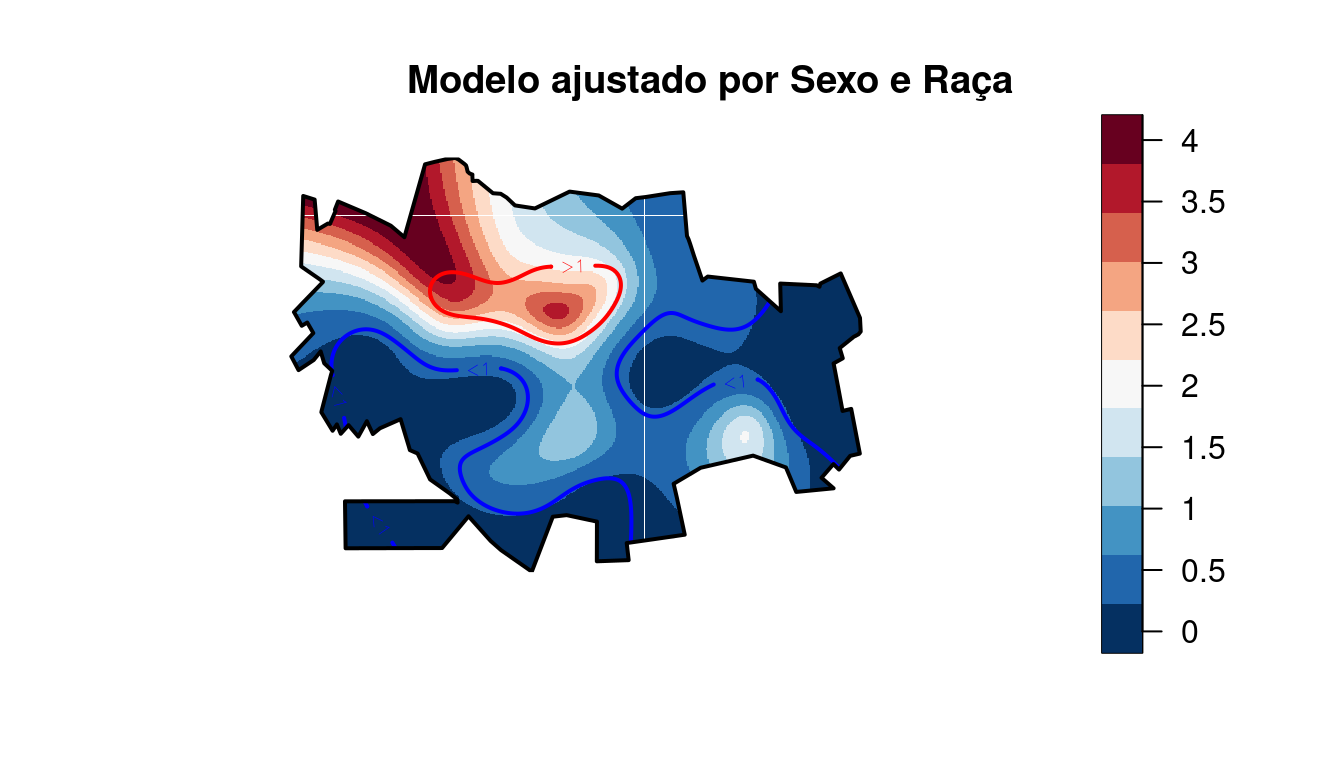
Incluindo no modelo a variável sexo:
mod1 <- gam(CLASSI_FIN == 1 ~ CS_SEXO + factor(CS_RACA) +
s(X, Y), data = casos.pt, family = binomial)
Family: binomial
Link function: logit
Formula:
CLASSI_FIN == 1 ~ CS_SEXO + factor(CS_RACA) + s(X, Y)
Parametric coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.9830 0.1097 8.96 <2e-16 ***
CS_SEXOM -0.0215 0.1530 -0.14 0.888
factor(CS_RACA)2 -0.6188 0.3746 -1.65 0.099 .
factor(CS_RACA)3 -0.2041 0.9833 -0.21 0.836
factor(CS_RACA)4 0.2949 0.2099 1.41 0.160
factor(CS_RACA)5 -0.5668 1.1361 -0.50 0.618
factor(CS_RACA)9 0.8469 0.8517 0.99 0.320
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Approximate significance of smooth terms:
edf Ref.df Chi.sq p-value
s(X,Y) 21.8 26.2 143 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
R-sq.(adj) = 0.162 Deviance explained = 15.2%
UBRE = 0.094684 Scale est. = 1 n = 1011Como já visto anteriormente na análise exploratória espacial de pontos, a variável sexo não é significativa.
newgam <- data.frame(X = grade[, 1], Y = grade[, 2],
CS_SEXO = "F", CS_RACA = "1")
gg.pred <- predict(mod1, newdata = newgam, type = "terms",
terms = "s(X,Y)", se.fit = T)
gg.pred$fit[inside == F] <- NA
gg.pred$se.fit[inside == F] <- NA
z <- exp(matrix(gg.pred$fit, TAM, TAM))
## a very rough estimate of confidence intervals
z.inf <- exp(gg.pred$fit + (1.96 * gg.pred$se.fit))
z.sup <- exp(gg.pred$fit - (1.96 * gg.pred$se.fit))
z.inf <- matrix(z.inf, TAM, TAM)
z.sup <- matrix(z.sup, TAM, TAM)
invisible(split.screen(rbind(c(0, 0.8, 0, 1), c(0.8,
1, 0, 1))))
screen(1)
image(x, y, z, zlim = range(z, na.rm = T), col = cores,
asp = 1, xlab = "", ylab = "", main = "", axes = F)
# points(den$x_coord, den$y_coord, pch=19,
# col='blue', cex=0.1)
contour(x, y, z.inf, nlevels = 1, add = T, col = "blue",
lwd = 2, levels = 1, cex = 0.1, labels = "<1")
contour(x, y, z.sup, nlevels = 1, add = T, col = "red",
lwd = 2, levels = 1, cex = 0.1, labels = ">1")
splancs::polymap(contorno.xy, add = T, lwd = 2)
screen(2) # The legend
# range(z, na.rm=T) # to make a pretty legend
# ticks <- seq(0,0.5,by=0.2)
ticks <- quantile(na.omit(as.vector(z)), prob = seq(0,
1, by = 1/3))
ticks <- seq(0, 5, by = 0.5)
image.plot(zlim = range(z, na.rm = T), col = cores,
axis.args = list(at = ticks, labels = ticks), legend.only = TRUE,
smallplot = c(0.1, 0.25, 0.15, 0.85), legend.width = 3,
legend.shrink = 0.8, horizontal = F)
title("Modelo ajustado por Sexo e Raça")