4 Limpeza, manipulação e transformação dos dados
Dados podem ser organizados de diversas formas. No campo da Epidemiologia, o formato mais comum é o tabular. Porém, muitas vezes nos deparamos com “tabelas” que não estão no formato adequado para a análise e produção de gráficos. Veja a planilha abaixo, por exemplo:
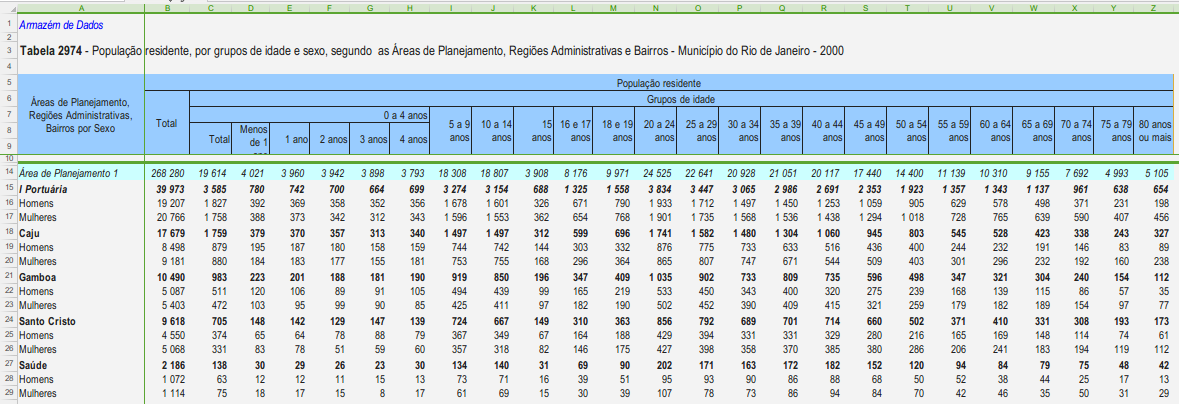
Observe que:
- Existem linhas com texto antes do início da tabela
- Existem células mescladas
- Cada linha representa coisas diferentes, como uma AP, uma região administrativa, um bairro, e sexo
- As colunas representam uma mesma variável (população residente) para cada faixa etária, mas incluindo também uma coluna para o total e para o total de 0 a 4 anos
- Tem mais de uma coluna com o mesmo nome (“Total”)
- Os nomes das colunas são longos demais e/ou tem espaços
- Algumas colunas tem nomes que começam com numeral
Que tipos de problemas podemos ter ao tentar abrir uma planilha dessas no R?
Imediatamente pensamos que o R não conseguirá identificar corretamente os nomes das colunas.
E para as análises? Vamos supor que você queira calcular a população de 80 anos ou mais do Rio de Janeiro. Se você fizesse um sum() da coluna “80 anos ou mais”, o resultado estaria correto? Por que?
Agora conseguimos entender a importância de ter os dados arrumados! Para isso, podemos contar com o tidyverse, que possui funções poderosas e permitem um fluxo intuitivo para tornar os dados tidy (organizados). Vamos relembrar a filosofia da tidy data:
- Cada variável é uma coluna; cada coluna é uma variável.
- Cada observação é uma linha; cada linha é uma observação.
- Cada valor é uma célula; cada célula é um único valor.
Assim, o conjunto de linhas forma uma tabela.
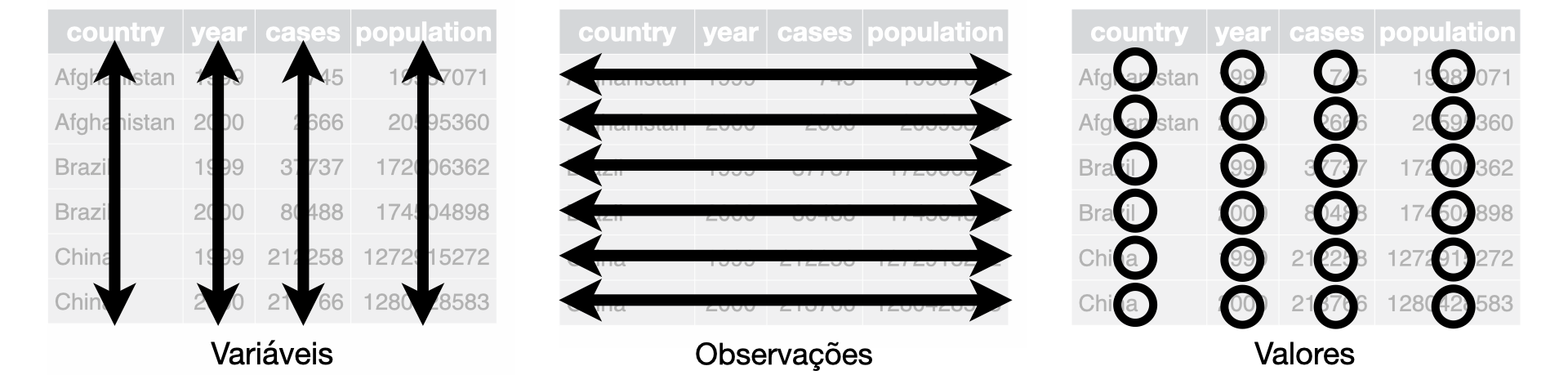 Crédito: R para Ciência de dados (2ª edição), por Wickham, Çetinkaya-Rundel, e Grolemund.
Crédito: R para Ciência de dados (2ª edição), por Wickham, Çetinkaya-Rundel, e Grolemund.
Os principais pacotes do tidyverse que são empregados para arrumar dados são o tidyr e o dplyr. Vamos conhecer um pouco deles a seguir. Mas primeiro, vamos voltar ao tibble e conhecê-lo um pouco melhor e usar o readr para importar dados.
4.1 Criando uma tabela com tibble

Uma tibble (tbl_df) é uma classe de objeto criada como um data.frame mais moderno, mantendo o que ele tem de positivo e mudando aspectos que os autores julgaram obsoletos ou não funcionais. Ele não substitui todos os métodos providos pelo data.frame. No entanto, o tibble é mais rápido e possui métodos aprimorados e mais modernos, seguros para utilizar e exibir tabelas, e compatível com os pacotes e funções dentro do tidyverse. Saiba mais AQUI.
Vamos abaixo criar um tibble:
library(tidyverse)
IMC <- tibble(
nomes = c("João", "Maria", "Carlos", "Ana"),
idade = as.integer(c(27, 25, 29, 26)),
sexo = as.factor(c('M','F','M','F')),
altura = c(180, 170, 185, 169),
peso = c(92.3,71.1,88.5,63.6),
dt_nasc = lubridate::dmy(c('03/08/1990','15/12/1992','05-07-1988','06-08-1991')) ,
exercicio = c(TRUE, FALSE, FALSE, TRUE)
)O comando acima usa a função tibble() para criar um tibble a partir de vetores, similar ao que faríamos com data.frame().
Vamos verificar agora o conteúdo desse objeto:
IMC
# A tibble: 4 × 7
nomes idade sexo altura peso dt_nasc exercicio
<chr> <int> <fct> <dbl> <dbl> <date> <lgl>
1 João 27 M 180 92.3 1990-08-03 TRUE
2 Maria 25 F 170 71.1 1992-12-15 FALSE
3 Carlos 29 M 185 88.5 1988-07-05 FALSE
4 Ana 26 F 169 63.6 1991-08-06 TRUE Note que em primeiro lugar no output já nos é informado que o objeto é um tibble com 4 linhas e 7 colunas. Abaixo do nome de cada coluna temos o tipo da variável, se é caractere, numérico (double ou integer), fator, data ou lógico. Outra característica importante é que por padrão nenhum caractere é convertido para fator como acontece quando se usa data.frame().
Vamos ver a classe a que pertence esse objeto:
class(IMC)
[1] "tbl_df" "tbl" "data.frame"Repare que ele também pertence a classe data.frame, assim a grande maioria das funções que usamos para manusear objetos da classe data.frame podem ser empregados também na classe tbl_df (com algumas diferenças).
Para ilustrar as similaridades, vamos em primeiro lugar converter um data.frame e criar um objeto tibble.
iris_tb <- as_tibble(iris)
class(iris_tb)
[1] "tbl_df" "tbl" "data.frame"Vamos testar a indexação de ambas as classes
# data.frame
iris$Species
[1] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[11] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[21] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[31] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[41] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[51] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[61] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[71] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[81] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[91] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[101] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[111] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[121] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[131] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[141] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
Levels: setosa versicolor virginica
# tibble
iris_tb$Species
[1] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[11] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[21] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[31] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[41] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[51] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[61] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[71] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[81] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[91] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[101] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[111] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[121] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[131] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[141] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
Levels: setosa versicolor virginica# data.frame
iris[[4]]
[1] 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 0.2 0.2 0.1 0.1 0.2 0.4 0.4 0.3 0.3 0.3 0.2 0.4 0.2 0.5 0.2 0.2 0.4 0.2 0.2
[30] 0.2 0.2 0.4 0.1 0.2 0.2 0.2 0.2 0.1 0.2 0.2 0.3 0.3 0.2 0.6 0.4 0.3 0.2 0.2 0.2 0.2 1.4 1.5 1.5 1.3 1.5 1.3 1.6 1.0
[59] 1.3 1.4 1.0 1.5 1.0 1.4 1.3 1.4 1.5 1.0 1.5 1.1 1.8 1.3 1.5 1.2 1.3 1.4 1.4 1.7 1.5 1.0 1.1 1.0 1.2 1.6 1.5 1.6 1.5
[88] 1.3 1.3 1.3 1.2 1.4 1.2 1.0 1.3 1.2 1.3 1.3 1.1 1.3 2.5 1.9 2.1 1.8 2.2 2.1 1.7 1.8 1.8 2.5 2.0 1.9 2.1 2.0 2.4 2.3
[117] 1.8 2.2 2.3 1.5 2.3 2.0 2.0 1.8 2.1 1.8 1.8 1.8 2.1 1.6 1.9 2.0 2.2 1.5 1.4 2.3 2.4 1.8 1.8 2.1 2.4 2.3 1.9 2.3 2.5
[146] 2.3 1.9 2.0 2.3 1.8
# tibble
iris_tb[[4]]
[1] 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 0.2 0.2 0.1 0.1 0.2 0.4 0.4 0.3 0.3 0.3 0.2 0.4 0.2 0.5 0.2 0.2 0.4 0.2 0.2
[30] 0.2 0.2 0.4 0.1 0.2 0.2 0.2 0.2 0.1 0.2 0.2 0.3 0.3 0.2 0.6 0.4 0.3 0.2 0.2 0.2 0.2 1.4 1.5 1.5 1.3 1.5 1.3 1.6 1.0
[59] 1.3 1.4 1.0 1.5 1.0 1.4 1.3 1.4 1.5 1.0 1.5 1.1 1.8 1.3 1.5 1.2 1.3 1.4 1.4 1.7 1.5 1.0 1.1 1.0 1.2 1.6 1.5 1.6 1.5
[88] 1.3 1.3 1.3 1.2 1.4 1.2 1.0 1.3 1.2 1.3 1.3 1.1 1.3 2.5 1.9 2.1 1.8 2.2 2.1 1.7 1.8 1.8 2.5 2.0 1.9 2.1 2.0 2.4 2.3
[117] 1.8 2.2 2.3 1.5 2.3 2.0 2.0 1.8 2.1 1.8 1.8 1.8 2.1 1.6 1.9 2.0 2.2 1.5 1.4 2.3 2.4 1.8 1.8 2.1 2.4 2.3 1.9 2.3 2.5
[146] 2.3 1.9 2.0 2.3 1.8# data.frame
iris[['Species']]
[1] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[11] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[21] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[31] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[41] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[51] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[61] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[71] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[81] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[91] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[101] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[111] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[121] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[131] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[141] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
Levels: setosa versicolor virginica
# tibble
iris_tb[['Species']]
[1] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[11] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[21] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[31] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[41] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
[51] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[61] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[71] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[81] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[91] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[101] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[111] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[121] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[131] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
[141] virginica virginica virginica virginica virginica virginica virginica virginica virginica virginica
Levels: setosa versicolor virginicaComo se pode notar o comportamento foi idêntico entre ambas as classes. Agora vejamos o que acontece abaixo:
iris$Sepal.L
[1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4 5.1 5.7 5.1 5.4 5.1 4.6 5.1 4.8 5.0 5.0 5.2 5.2
[30] 4.7 4.8 5.4 5.2 5.5 4.9 5.0 5.5 4.9 4.4 5.1 5.0 4.5 4.4 5.0 5.1 4.8 5.1 4.6 5.3 5.0 7.0 6.4 6.9 5.5 6.5 5.7 6.3 4.9
[59] 6.6 5.2 5.0 5.9 6.0 6.1 5.6 6.7 5.6 5.8 6.2 5.6 5.9 6.1 6.3 6.1 6.4 6.6 6.8 6.7 6.0 5.7 5.5 5.5 5.8 6.0 5.4 6.0 6.7
[88] 6.3 5.6 5.5 5.5 6.1 5.8 5.0 5.6 5.7 5.7 6.2 5.1 5.7 6.3 5.8 7.1 6.3 6.5 7.6 4.9 7.3 6.7 7.2 6.5 6.4 6.8 5.7 5.8 6.4
[117] 6.5 7.7 7.7 6.0 6.9 5.6 7.7 6.3 6.7 7.2 6.2 6.1 6.4 7.2 7.4 7.9 6.4 6.3 6.1 7.7 6.3 6.4 6.0 6.9 6.7 6.9 5.8 6.8 6.7
[146] 6.7 6.3 6.5 6.2 5.9
iris_tb$Sepal.L
NULL
Warning:
Unknown or uninitialised column: `Sepal.L`. O que aconteceu? Você sabe explicar?
Com um
data.framepodemos nos referir ao nome de uma coluna de uma maneira parcial, desde que o nome seja inequívoco, no exemplo acimairis$Sepal.Lmostra somente a colunaSepal.Length, no entanto essa maneira não funciona nos objetostibble.
Uma outra diferença importante está no fato de que se pedirmos uma coluna inexistente a um data.frame, ele retorna NULL, no entanto não há nenhum erro e nem warning. Já o tibble retorna NULL e gera um warning, o que é importante quando estamos desenvolvendo funções.
iris$z # retorna NULL e não gera warning
NULL
iris_tb$z # Warning
NULL
Warning:
Unknown or uninitialised column: `z`.Além da função tibble(), existe a função tribble() (abreviação de transposed tibble) que permite criar um tibble linha por linha:
zika <- tribble(
~UF, ~Casos, ~Incidencia,
"MG", 15211, 72.9,
"ES", 2321, 59.1,
"RJ", 67481, 407.7,
"SP", 5612, 12.6
)
zika
# A tibble: 4 × 3
UF Casos Incidencia
<chr> <dbl> <dbl>
1 MG 15211 72.9
2 ES 2321 59.1
3 RJ 67481 408.
4 SP 5612 12.6Repare que ao invés de especificarmos as variáveis, entramos com cada linha, sendo que a primeira linha deve ter o nome de cada coluna precedida por um ~ (til).
Para vermos a estrutura dos dados podemos usar a função glimpse() que é a correspondente a função str() do módulo base.
glimpse(zika)
Rows: 4
Columns: 3
$ UF <chr> "MG", "ES", "RJ", "SP"
$ Casos <dbl> 15211, 2321, 67481, 5612
$ Incidencia <dbl> 72.9, 59.1, 407.7, 12.6Apesar de não existirem grandes diferenças entre data.frame e tibble, a velocidade, segurança e facilidades na visualização, além do fato de pertencer ao tidyverse e seu ecossistema de pacotes, são bons motivos para sua utilização.
4.2 Importando dados com o readr

O readr é o pacote do tidyverse responsável por prover maneiras rápidas e amigáveis para importar dados tabulares no R de diversos formatos (como csv, tsv e fwf). Suas funções são desenhadas com flexibilidade para identificar os tipos de cada coluna e facilitar a identificação de problemas dentro dos dados.
O processo de importação de dados passa por 3 estágios básicos:
- Leitura em um formato “retangular”, ou seja uma matriz de strings
- Determinação do tipo de cada coluna (numérico, data)
- Transformações necessárias a cada coluna dado seu tipo (exemplo: conversão de string para numérico)
O pacote readr faz isso de uma maneira muito mais rápida que as tracionais funções do pacote básico do R. Além do mais, permite facilmente especificar o formato das colunas de uma maneira mais simples e precisa.
As pricipais funções do readr para ler dados são:
read_table(): para colunas separadas por espaçoread_csv()eread_csv2(): para arquivos do tipo .csv com colunas separadas por ‘,’ e ‘;’, respectivamenteread_tsv(): para arquivos tsv (tab-separated values), separados por tabulação (read_fwf(): para arquivos com formato fixo (fixed-width format)read_delim(): genérica, para quando o delimitador não é ‘,’, ‘;’, espaço ou tab. Deve-se especificar o delimitador.
Todas as funções possuem diversas opções de parâmetros para melhor especificar o formato dos dados e importam os dados no formato tibble. Existem também todas as funções correspondente para salvar os dados (exemplo write_csv()). Saiba mais sobre o pacote readr AQUI.
4.2.1 Exemplo com TabNet
Muitas vezes trabalhamos com dados públicos de vigilância obtidos através do TabNet. Vamos então fazer o passo a passo desde a obtenção deste dados!
Para servir de exemplo, vamos pegar os dados de casos de AIDS no Brasil, que podem ser acessados aqui. Tratam-se de casos de AIDS notificados no SINAN, declarados no SIM e registrados no SISCEL/SILCOM.
Vamos selecionar para Linha o Munícipio de Residência, e para Coluna o ano de diagnóstico, e vamos selecionar todos os períodos disponíveis. 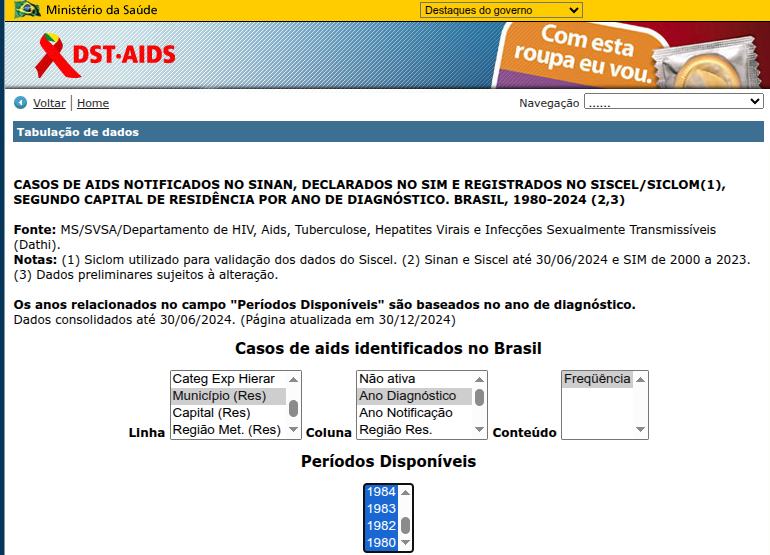
A tela seguinte dese se parecer com:
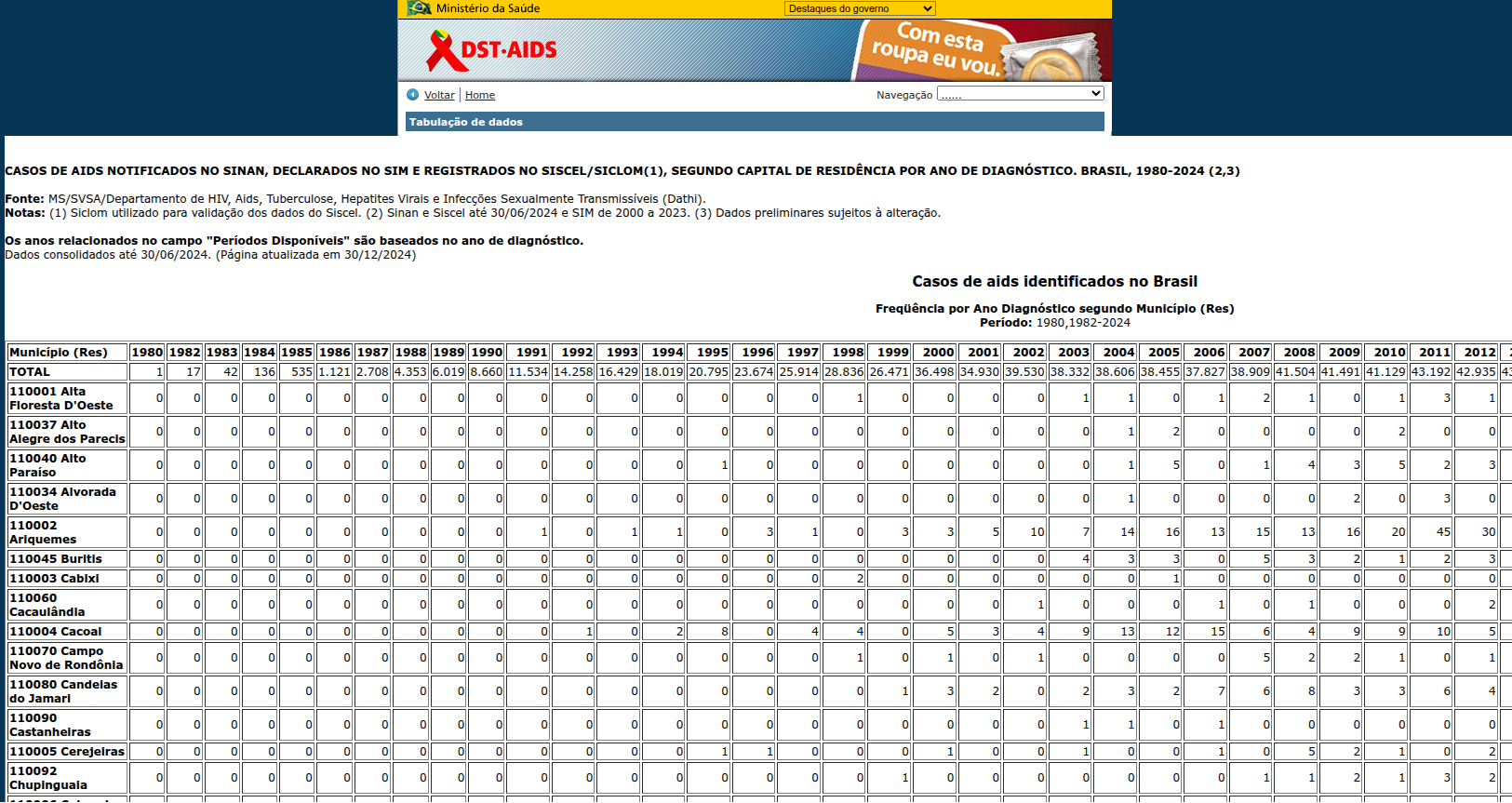
Role para baixo e baixe o arquivo .csv. Para fins deste exemplo, vamos chamá-lo de aids_1980-2024.csv.
Agora vamos importar este arquivo!
Este é um csv delimitado por “;”, então devemos usar a função read_csv2():
aids <- read_csv2('aids_1980-2024.csv')
ℹ Using "','" as decimal and "'.'" as grouping mark. Use `read_delim()` for more control.
Rows: 5504 Columns: 1
── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Delimiter: ";"
chr (1): Casos de aids identificados no Brasil
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Warning:
One or more parsing issues, call `problems()` on your data frame for details, e.g.:
dat <- vroom(...)
problems(dat) Opa! Recebemos de uma mensagem de erro! Além disso, o objeto ficou com somente uma coluna. Vamos inspecioná-lo:
aids
# A tibble: 5,504 × 1
`Casos de aids identificados no Brasil`
<chr>
1 "Freq\xfc\xeancia por Munic\xedpio (Res) e Ano Diagn\xf3stico"
2 "Per\xedodo:1980,1982-2024"
3 "Munic\xedpio (Res);1980;1982;1983;1984;1985;1986;1987;1988;1989;1990;1991;1992;1993;1994;1995;1996;1997;1998;1999;2000;2001;2002;2003;2004;2005;2006;2007;2008;…
4 "110001 Alta Floresta D'Oeste;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;1;0;0;0;0;1;1;0;1;2;1;0;1;3;1;2;2;0;0;1;1;0;1;0;2;5;0;26"
5 "110037 Alto Alegre dos Parecis;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;1;2;0;0;0;0;2;0;0;0;0;0;0;0;0;0;0;0;0;2;0;7"
6 "110040 Alto Para\xedso;0;0;0;0;0;0;0;0;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;1;5;0;1;4;3;5;2;3;1;1;1;1;0;1;1;0;1;1;2;0;35"
7 "110034 Alvorada D'Oeste;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;1;0;0;0;0;2;0;3;0;0;0;2;1;0;2;0;0;2;0;0;0;13"
8 "110002 Ariquemes;0;0;0;0;0;0;0;0;0;0;1;0;1;1;0;3;1;0;3;3;5;10;7;14;16;13;15;13;16;20;45;30;24;21;24;23;23;24;20;25;25;16;38;12;492"
9 "110045 Buritis;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;4;3;3;0;5;3;2;1;2;3;8;1;5;1;0;2;2;2;3;3;5;1;59"
10 "110003 Cabixi;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;2;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0;2;0;0;0;2;1;0;0;8"
# ℹ 5,494 more rows
# ℹ Use `print(n = ...)` to see more rowsQue problemas podemos identificar? Como podemos resolvê-los?
| Exemplo no dado | Problema identificado | Solução |
|---|---|---|
Casos de aids identificados no Brasil <chr> |
Cabeçalho original foi interpretado como nome da única coluna identificada | Pular linhas do cabeçalho, usando o argumento skip |
Primeiras linhas: "Freq…", "Período:1980,1982-2024" |
Mais linhas de cabeçalho, agora lidas como observações da variável Casos… |
Usar argumento skip = 3 para ignorar as 3 linhas de cabeçalho. |
"Freq\xfc\xeancia por Munic\xedpio (Res) e Ano Diagn\xf3stico" |
Encoding errado, acentuação e caracteres especiais quebrados | Usar locale(encoding = "latin1") ao ler o arquivo. |
Vamos tentar!
aids <- read_csv2('aids_1980-2024.csv',
skip = 3,
locale=locale(encoding='latin1'))
ℹ Using "','" as decimal and "'.'" as grouping mark. Use `read_delim()` for more control.
Rows: 5501 Columns: 46
── Column specification ─────────────────────────────────────────────────────
Delimiter: ";"
chr (1): Município (Res)
dbl (45): 1980, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989, 1990, 199...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
aids
# A tibble: 5,501 × 46
`Município (Res)` `1980` `1982` `1983` `1984` `1985` `1986` `1987` `1988`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 110001 Alta Flore… 0 0 0 0 0 0 0 0
2 110037 Alto Alegr… 0 0 0 0 0 0 0 0
3 110040 Alto Paraí… 0 0 0 0 0 0 0 0
4 110034 Alvorada D… 0 0 0 0 0 0 0 0
5 110002 Ariquemes 0 0 0 0 0 0 0 0
6 110045 Buritis 0 0 0 0 0 0 0 0
7 110003 Cabixi 0 0 0 0 0 0 0 0
8 110060 Cacaulândia 0 0 0 0 0 0 0 0
9 110004 Cacoal 0 0 0 0 0 0 0 0
10 110070 Campo Novo… 0 0 0 0 0 0 0 0
# ℹ 5,491 more rows
# ℹ 37 more variables: `1989` <dbl>, `1990` <dbl>, `1991` <dbl>,
# `1992` <dbl>, `1993` <dbl>, `1994` <dbl>, `1995` <dbl>, `1996` <dbl>,
# `1997` <dbl>, `1998` <dbl>, `1999` <dbl>, `2000` <dbl>, `2001` <dbl>,
# `2002` <dbl>, `2003` <dbl>, `2004` <dbl>, `2005` <dbl>, `2006` <dbl>,
# `2007` <dbl>, `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>,
# `2012` <dbl>, `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, …
# ℹ Use `print(n = ...)` to see more rowsParece que está tudo OK! E a função parece ter identificado corretamente o tipo das variáveis. Se não fosse o caso, poderíamos espeficar usando o argumento col_types.
MAS este é um dado tidy? Vamos, então, usar o próximo pacote para a arrumação destes dados!
4.3 Transformando a estrutura dos dados com tidyr

O tidyr é o pacote do tidyverse focado em ajudar a transformar os dados para o formato tidy (arrumado). As principais funções são:
pivot_longer(): colapsa as colunas para linhaspivot_wider(): transforma linhas em colunasseparate_wider_position()eseparate_wider_delim(): separa uma coluna em múltiplasunite(): une várias colunas em uma
Saiba mais sobre o tidyr AQUI.
De cara, já conseguiu identificar que funções podemos aplicar aos dados aids? Vamos começar!
4.3.1 pivot_longer()
Podemos transformar as diversas colunas contendo indicadores em duas, uma contendo o nome do indicador e a outra o valor. Para isso usaremos a função pivot_longer().
Como vimos antes, em um dado tidy cada variável é uma coluna. No entanto, temos em várias colunas a informação de número de casos notificados de aids, sendo uma para cada ano. Vamos usar esta função para corrigir isso:
aids.longo <- aids %>%
pivot_longer(
cols = -`Município (Res)`,
names_to = "ano",
values_to = "casos"
)
aids.longo
# A tibble: 247,545 × 3
`Município (Res)` ano casos
<chr> <chr> <dbl>
1 110001 Alta Floresta D'Oeste 1980 0
2 110001 Alta Floresta D'Oeste 1982 0
3 110001 Alta Floresta D'Oeste 1983 0
4 110001 Alta Floresta D'Oeste 1984 0
5 110001 Alta Floresta D'Oeste 1985 0
6 110001 Alta Floresta D'Oeste 1986 0
7 110001 Alta Floresta D'Oeste 1987 0
8 110001 Alta Floresta D'Oeste 1988 0
9 110001 Alta Floresta D'Oeste 1989 0
10 110001 Alta Floresta D'Oeste 1990 0
# ℹ 247,535 more rows
# ℹ Use `print(n = ...)` to see more rowsObserve que todas as colunas menos o município de residência foram colapsadas em duas variáveis, uma com o ano e outra com o número de casos.
Esse formato acima é o mais indicado para banco de dados e permite filtrar mais rapidamente, por exemplo, um indicador que você deseja. Esse também é o formato que a ggplot() gosta que os dados estejam!
4.3.2 pivot_wider()
Em algumas situações, por exemplo, para fazer um modelo GLM, é mais cômodo que os dados esteja em colunas distintas. Podemos usar, então, a função pivot_wider() para tornar os dados largos. Veja no exemplo abaixo como retornar ao formato original:
aids.longo %>%
pivot_wider(
names_from = ano,
values_from = casos
)
# A tibble: 5,501 × 46
`Município (Res)` `1980` `1982` `1983` `1984` `1985` `1986` `1987` `1988` `1989`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 110001 Alta Flores… 0 0 0 0 0 0 0 0 0
2 110037 Alto Alegre… 0 0 0 0 0 0 0 0 0
3 110040 Alto Paraíso 0 0 0 0 0 0 0 0 0
4 110034 Alvorada D'… 0 0 0 0 0 0 0 0 0
5 110002 Ariquemes 0 0 0 0 0 0 0 0 0
6 110045 Buritis 0 0 0 0 0 0 0 0 0
7 110003 Cabixi 0 0 0 0 0 0 0 0 0
8 110060 Cacaulândia 0 0 0 0 0 0 0 0 0
9 110004 Cacoal 0 0 0 0 0 0 0 0 0
10 110070 Campo Novo … 0 0 0 0 0 0 0 0 0
# ℹ 5,491 more rows
# ℹ 36 more variables: `1990` <dbl>, `1991` <dbl>, `1992` <dbl>, `1993` <dbl>,
# `1994` <dbl>, `1995` <dbl>, `1996` <dbl>, `1997` <dbl>, `1998` <dbl>,
# `1999` <dbl>, `2000` <dbl>, `2001` <dbl>, `2002` <dbl>, `2003` <dbl>,
# `2004` <dbl>, `2005` <dbl>, `2006` <dbl>, `2007` <dbl>, `2008` <dbl>,
# `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, `2013` <dbl>,
# `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>, `2018` <dbl>, …4.3.3 separate_wider_position() e separate_wider_delim()
Repare que a coluna Município (Res) possui dois tipos de informação: o código do município e o nome do município. É útil ter essas informações separadas, por exemplo, para usar o código do município como chave para juntar com outras tabelas, e para usar o nome do município como rótulo (label) de gráficos.
A função separate_wider_delim() permite separar a coluna especificando um delimitador, enquanto a separate_wider_position() separa especificando um cumprimento fixo.
Vamos tentar usando a separate_wider_delim(). Como temos mais de um ” ” na variável, precisamos incluir o argumento too_many = 'merge para unir os demais “pedaços”:
aids.longo %>%
separate_wider_delim(cols = `Município (Res)`,
names = c("cod_mun_res", "mun_res"),
delim = " ", too_many = "merge")
Error in `separate_wider_delim()`:
! Expected 2 pieces in each element of `Município (Res)`.
! 45 values were too short.
ℹ Use `too_few = "debug"` to diagnose the problem.
ℹ Use `too_few = "align_start"/"align_end"` to silence this message.
Run `rlang::last_trace()` to see where the error occurred.Recebemos um aviso de erro! Vamos lê-lo com calma. Nós consideramos a existência de mais de um espaço na variável, mas aparentemente tem valores com nenhum espaço! Neste caso, a mensagem sugere usar too_few = "debug" para investigar melhor o problema. Tentem fazer isso em casa!
Vamos adiantar e incluir a opção too_few = "align_end":
aids.longo <- aids.longo %>%
separate_wider_delim(cols = `Município (Res)`,
names = c("cod_mun_res", "mun_res"),
delim = " ",
too_many = "merge",
too_few = "align_end") Não houve mensagem de aviso. Vamos inspecionar o objeto:
aids.longo
# A tibble: 247,545 × 4
cod_mun_res mun_res ano casos
<chr> <chr> <chr> <dbl>
1 110001 Alta Floresta D'Oeste 1980 0
2 110001 Alta Floresta D'Oeste 1982 0
3 110001 Alta Floresta D'Oeste 1983 0
4 110001 Alta Floresta D'Oeste 1984 0
5 110001 Alta Floresta D'Oeste 1985 0
6 110001 Alta Floresta D'Oeste 1986 0
7 110001 Alta Floresta D'Oeste 1987 0
8 110001 Alta Floresta D'Oeste 1988 0
9 110001 Alta Floresta D'Oeste 1989 0
10 110001 Alta Floresta D'Oeste 1990 0
# ℹ 247,535 more rows
# ℹ Use `print(n = ...)` to see more rows
tail(aids.longo)
# A tibble: 6 × 4
cod_mun_res mun_res ano casos
<chr> <chr> <chr> <dbl>
1 NA Total 2020 30684
2 NA Total 2021 35550
3 NA Total 2022 37049
4 NA Total 2023 37994
5 NA Total 2024 17884
6 NA Total Total 1165423Vejam o que causou o erro! Mais uma desconformidade em relação a dados tidy. A coluna original de Muncípio de residência não apenas representava seu código e nome, mas também o Total! Os dados originais também continham uma coluna “Total”, que acabou ficando transposta na variável que criamos “ano”. Vamos corrigir isso em breve usando funções do dplyr!
Agora vamos supor que quiséssemos separar os dois primeiros dígitos do código do munícipio em uma outra variável, representando o código da Unidade Federativa. Poderíamos fazer com separate_wider_position():
aids.separado <- aids2 %>%
separate_wider_position(cols = cod_mun_res,
widths = c(cod_uf_res = 2, cod_mun_res4 = 4),
too_few = "align_start")
aids.separado
# A tibble: 247,545 × 5
cod_uf_res cod_mun_res4 mun_res ano casos
<chr> <chr> <chr> <chr> <dbl>
1 11 0001 Alta Floresta D'Oeste 1980 0
2 11 0001 Alta Floresta D'Oeste 1982 0
3 11 0001 Alta Floresta D'Oeste 1983 0
4 11 0001 Alta Floresta D'Oeste 1984 0
5 11 0001 Alta Floresta D'Oeste 1985 0
6 11 0001 Alta Floresta D'Oeste 1986 0
7 11 0001 Alta Floresta D'Oeste 1987 0
8 11 0001 Alta Floresta D'Oeste 1988 0
9 11 0001 Alta Floresta D'Oeste 1989 0
10 11 0001 Alta Floresta D'Oeste 1990 0Perceba que como temos NA na coluna cod_mun_res, precisamos especificar too_few = "align_start", ou recebemos uma mensagem de erro.
IMPORTANTE! Essas funções estão em fase experimental para substituir a função separate, que está sendo descontinuada. Portanto, é provável que ainda passem por modificações.
4.3.4 unite()
A função unite() permite unir colunas usando um separador. Vamos voltar a unir o código da UF com o identificador de 4 dígitos do município para voltar a ter o seu código completo:
aids.separado %>%
unite("cod_mun_res", cod_uf_res:cod_mun_res4, sep = "")
# A tibble: 247,545 × 4
cod_mun_res mun_res ano casos
<chr> <chr> <chr> <dbl>
1 110001 Alta Floresta D'Oeste 1980 0
2 110001 Alta Floresta D'Oeste 1982 0
3 110001 Alta Floresta D'Oeste 1983 0
4 110001 Alta Floresta D'Oeste 1984 0
5 110001 Alta Floresta D'Oeste 1985 0
6 110001 Alta Floresta D'Oeste 1986 0
7 110001 Alta Floresta D'Oeste 1987 0
8 110001 Alta Floresta D'Oeste 1988 0
9 110001 Alta Floresta D'Oeste 1989 0
10 110001 Alta Floresta D'Oeste 1990 0
# ℹ 247,535 more rows
# ℹ Use `print(n = ...)` to see more rows4.4 Manipulando dados com dplyr

O dplyr é um poderoso pacote do tidyverse voltado para a manipulação de dados tabulares no R. Possui um conjunto de funções para filtrar, ordenar, resumir, agrupar, entre outras operações. Veja as principais abaixo:
| Função | O que faz | Exemplo |
|---|---|---|
filter() |
Filtra linhas que atendem a uma condição | filter(dados, idade > 30) |
select() |
Seleciona colunas específicas | select(dados, nome, idade) |
mutate() |
Cria ou modifica colunas | mutate(dados, idade_10 = idade + 10) |
arrange() |
Ordena linhas | arrange(dados, desc(idade)) |
summarise() / summarize() |
Calcula resumos (média, soma etc.) | summarise(dados, media_idade = mean(idade)) |
group_by() |
Agrupa dados para cálculos por grupo | group_by(dados, cidade) |
distinct() |
Retira linhas duplicadas | distinct(dados, cidade) |
rename() |
Renomeia colunas | rename(dados, nome_cidade = cidade) |
Para saber mais sobre o dplyr, clique AQUI.
Agora vamos usar essas funções para manipular os dados do exemplo anterior de casos notificados de AIDS, e de dados do censo.
4.4.1 filter()
Vamos usar a função filter(), que filtra as linhas que atendem o critério especificado. Veja:
aids.longo |>
filter(cod_mun_res == '261160')
# A tibble: 45 × 4
cod_mun_res mun_res ano casos
<chr> <chr> <chr> <dbl>
1 261160 Recife 1980 0
2 261160 Recife 1982 0
3 261160 Recife 1983 1
4 261160 Recife 1984 1
5 261160 Recife 1985 7
6 261160 Recife 1986 14
7 261160 Recife 1987 66
8 261160 Recife 1988 90
9 261160 Recife 1989 164
10 261160 Recife 1990 106
# ℹ 35 more rows
# ℹ Use `print(n = ...)` to see more rowsCom o comando acima selecionamos apenas os casos notificados com residência em Recife. Podemos também combinar critérios, como, por exemplo:
aids.longo |>
filter(cod_mun_res == '261160', ano >= '2020')
# A tibble: 5 × 4
cod_mun_res mun_res ano casos
<chr> <chr> <chr> <dbl>
1 261160 Recife 2020 398
2 261160 Recife 2021 511
3 261160 Recife 2022 483
4 261160 Recife 2023 438
5 261160 Recife 2024 181A saída nos mostra quantos casos de AIDS por ano foram registrados em Recife de 2020 a 2024.
Repare que múltiplos critérios são equivalentes ao operador AND (&). Você pode utilizar o operador OU (“|”) para selecionar observações com um ou outro critério.
Lembrando os operadores lógicos e como usá-los no R:
| Operador Logico | R |
Significado |
|---|---|---|
| EQUAL | == | IGUAL |
| AND | & | E |
| OR | | | OU |
| XOR | xor() | OU EXCLUSIVO |
| NOT | ! | NÃO |
Retomando, a função filter() é útil tanto para filtrar apenas as observações de interesse de uma tabela, como também para realizar limpeza de dados importados, como no exemplo a seguir.
Lembra que nosso objeto aids.longo possui valores “Total” nas colunas mun_res e ano?
aids.longo |> tail()
# A tibble: 6 × 4
cod_mun_res mun_res ano casos
<chr> <chr> <chr> <dbl>
1 NA Total 2020 30684
2 NA Total 2021 35550
3 NA Total 2022 37049
4 NA Total 2023 37994
5 NA Total 2024 17884
6 NA Total Total 1165423Vamos usar filter() para excluir essas linhas da nossa tabela:
aids.longo <- aids.longo |>
filter(mun_res != "Total",
ano != "Total")
aids.longo |>
tail()
# A tibble: 6 × 4
cod_mun_res mun_res ano casos
<chr> <chr> <chr> <dbl>
1 530010 Brasília 2019 461
2 530010 Brasília 2020 385
3 530010 Brasília 2021 437
4 530010 Brasília 2022 423
5 530010 Brasília 2023 437
6 530010 Brasília 2024 176Pronto! Agora a nossa tabela está livre dos valores totais.
EXTRA: Você deve ter reparado que o dado pula de 1980 para 1981 nas primeiras obervações. Será que alguns municípios estão sem os dados de 1981? Podemos usar filter() para verificar:
aids.longo |>
filter(ano == 1981)
# A tibble: 0 × 4
# ℹ 4 variables: cod_mun_res <chr>, mun_res <chr>, ano <chr>, casos <dbl>Não tem nenhum município com dados de 1981! Aparentemente é um problema no TabNet, pois o ano de 1981 não aparece nas opções de Períodos Disponíveis.
4.4.2 select()
Agora vamos imaginar que eu queira uma tabela apenas com os códigos e nomes dos municípios que registraram ao menos 1 caso de AIDS em 2024. A função select() seleciona as colunas desejadas, e também especifica sua ordem de saída.
aids.longo |>
filter(casos > 0, ano == 2024, ) |>
select(mun_res, cod_mun_res)
# A tibble: 2,352 × 2
mun_res cod_mun_res
<chr> <chr>
1 Ariquemes 110002
2 Buritis 110045
3 Cacaulândia 110060
4 Cacoal 110004
5 Candeias do Jamari 110080
6 Cerejeiras 110005
7 Colorado do Oeste 110006
8 Espigão D'Oeste 110009
9 Guajará-Mirim 110010
10 Jaru 110011
# ℹ 2,342 more rows
# ℹ Use `print(n = ...)` to see more rowsPerceba que a ordem das colunas mudou para a ordem que aparecem dentro de select().
Também podemos usar select para excluir uma variável usando o sinal de menos “-”:
aids.longo |>
filter(casos > 0, ano == 2024, ) |>
select(-ano, - casos)
# A tibble: 2,352 × 2
cod_mun_res mun_res
<chr> <chr>
1 110002 Ariquemes
2 110045 Buritis
3 110060 Cacaulândia
4 110004 Cacoal
5 110080 Candeias do Jamari
6 110005 Cerejeiras
7 110006 Colorado do Oeste
8 110009 Espigão D'Oeste
9 110010 Guajará-Mirim
10 110011 Jaru
# ℹ 2,342 more rows
# ℹ Use `print(n = ...)` to see more rowsTambém é possível selecionar colunas em um intervalo usando “:” ou ainda usar a posição da coluna:
aids.longo |>
select (c(1,3,4))
# A tibble: 242,000 × 3
cod_mun_res ano casos
<chr> <chr> <dbl>
1 110001 1980 0
2 110001 1982 0
3 110001 1983 0
4 110001 1984 0
5 110001 1985 0
6 110001 1986 0
7 110001 1987 0
8 110001 1988 0
9 110001 1989 0
10 110001 1990 0
# ℹ 241,990 more rows
# ℹ Use `print(n = ...)` to see more rows4.4.3 summarise() ou summarize()
A função summarise() cria nova variável contendo uma estatística resumo para uma determinada coluna em um dado tabular.
Vamos criar algumas variáveis a partir da contagem de casos de AIDS:
aids.longo |>
summarise(media_casos = mean(casos),
mediana_casos = median(casos),
max_casos = max(casos),
min_casos = min(casos))
# A tibble: 1 × 4
media_casos mediana_casos max_casos min_casos
<dbl> <dbl> <dbl> <dbl>
1 4.82 0 5362 0A função summarise() atinge seu potencial máximo quando usada em conjunto com comandos de agrupamento como veremos a seguir.
4.4.4 group_by()
A função group_by() é uma função muito importante que nos permite agrupar os dados. Em conjunto com summarise(), permite a criação de novas tabelas obtidas da agregação de dados.
Vamos agrupar os dados de AIDS para todo o Brasil, por ano:
aids.longo |>
group_by(ano) |>
summarise(total_casos = sum(casos),
max_casos = max(casos),
media_casos = mean(casos)) |>
print(n=20)
# A tibble: 44 × 4
ano total_casos max_casos media_casos
<chr> <dbl> <dbl> <dbl>
1 1980 1 1 0.000182
2 1982 17 4 0.00309
3 1983 42 22 0.00764
4 1984 136 73 0.0247
5 1985 535 277 0.0973
6 1986 1121 492 0.204
7 1987 2708 1051 0.492
8 1988 4353 1673 0.791
9 1989 6019 2214 1.09
10 1990 8660 2749 1.57
11 1991 11534 3195 2.10
12 1992 14258 3881 2.59
13 1993 16429 3885 2.99
14 1994 18019 3967 3.28
15 1995 20795 4091 3.78
16 1996 23674 4399 4.30
17 1997 25914 4510 4.71
18 1998 28836 4696 5.24
19 1999 26471 4142 4.81
20 2000 36498 5362 6.64
# ℹ 24 more rows
# ℹ Use `print(n = ...)` to see more rowsNo código acima agrupamos os dados por ano e calculamos o total de casos, o valor máximo registrado naquele ano em um município, e a média de casos. Adiciomanos print(n=20) para mostrar 20 observações.
4.4.5 rename()
Vamos agora trabalhar com dados do SIDRA, mas especificamente a Tabela 9922 - Domicílios particulares permanentes ocupados segundo a situação urbana/rural, para a Região Geográfica Imediata N25.
Para baixar os dados da API do SIDRA, vamos precisar da biblioteca jasonlite:
library(jsonlite)
url <- "https://apisidra.ibge.gov.br/values/t/9922/p/2022/v/382/C1/1,2/N25/all?formato=json"
populacao <- fromJSON(url)
head(populacao)
NC NN MC MN
1 Nível Territorial (Código) Nível Territorial Unidade de Medida (Código) Unidade de Medida
2 25 Região Geográfica Imediata 45 Pessoas
3 25 Região Geográfica Imediata 45 Pessoas
4 25 Região Geográfica Imediata 45 Pessoas
5 25 Região Geográfica Imediata 45 Pessoas
6 25 Região Geográfica Imediata 45 Pessoas
V D1C D1N D2C D2N
1 Valor Ano (Código) Ano Variável (Código) Variável
2 494869 2022 2022 382 Moradores em domicílios particulares permanentes ocupados
3 132299 2022 2022 382 Moradores em domicílios particulares permanentes ocupados
4 64889 2022 2022 382 Moradores em domicílios particulares permanentes ocupados
5 209556 2022 2022 382 Moradores em domicílios particulares permanentes ocupados
6 208836 2022 2022 382 Moradores em domicílios particulares permanentes ocupados
D3C D3N D4C
1 Situação do domicílio (Código) Situação do domicílio Região Geográfica Imediata (Código)
2 1 Urbana 110001
3 1 Urbana 110002
4 1 Urbana 110003
5 1 Urbana 110004
6 1 Urbana 110005
D4N
1 Região Geográfica Imediata
2 Porto Velho
3 Ariquemes
4 Jaru
5 Ji-Paraná
6 CacoalPerceba que a primeira linha corresponde ao nome da variável, e não ao início dos valores da tabela. Vamos agora passar uma sequência de ações nesta tabela:
populacao <- populacao |>
tibble() |>
slice(-1) |>
select(D4C,D4N,D1C,D3N,V) |>
rename(
cod_regim = D4C,
nome_regim = D4N,
ano = D1C,
situacao = D3N,
pop = V
)Vamos analisar em partes: primeiro convertemos o objeto em um tibble, depois usamos uma função do dplyr chamada slice() para remover a primeira linha da tabela, selecionamos com select() as variáveis de interesse, e, finalmente, renomeamos as colunas com a função rename(). O objeto ficou assim:
populacao
# A tibble: 1,020 × 5
cod_regim nome_regim ano situacao pop
<chr> <chr> <chr> <chr> <chr>
1 110001 Porto Velho 2022 Urbana 494869
2 110002 Ariquemes 2022 Urbana 132299
3 110003 Jaru 2022 Urbana 64889
4 110004 Ji-Paraná 2022 Urbana 209556
5 110005 Cacoal 2022 Urbana 208836
6 110006 Vilhena 2022 Urbana 127611
7 120001 Rio Branco 2022 Urbana 389623
8 120002 Brasiléia 2022 Urbana 44719
9 120003 Sena Madureira 2022 Urbana 36506
10 120004 Cruzeiro do Sul 2022 Urbana 96652
# ℹ 1,010 more rows
# ℹ Use `print(n = ...)` to see more rows4.4.6 mutate()
A função mutate() permite a modificação da tabela de dados, criando ou modificando variáveis já existentes.
Na tabela populacao, a variável pop está com o tipo caractere. Vamos utilizar mutate() para transformar em numérico:
populacao <- populacao |>
mutate(pop = as.numeric(pop))
populacao
# A tibble: 1,020 × 5
cod_regim nome_regim ano situacao pop
<chr> <chr> <chr> <chr> <dbl>
1 110001 Porto Velho 2022 Urbana 494869
2 110002 Ariquemes 2022 Urbana 132299
3 110003 Jaru 2022 Urbana 64889
4 110004 Ji-Paraná 2022 Urbana 209556
5 110005 Cacoal 2022 Urbana 208836
6 110006 Vilhena 2022 Urbana 127611
7 120001 Rio Branco 2022 Urbana 389623
8 120002 Brasiléia 2022 Urbana 44719
9 120003 Sena Madureira 2022 Urbana 36506
10 120004 Cruzeiro do Sul 2022 Urbana 96652
# ℹ 1,010 more rows
# ℹ Use `print(n = ...)` to see more rowsAgora vamos supor que queremos calcular a população total e a porcentagem do total que é população urbana. Como podemos fazer isso?
populacao <- populacao |>
pivot_wider(names_from = situacao,
values_from = pop) |>
mutate(Total = Urbana+Rural,
pct_urb = Urbana/Total*100)
populacao
# A tibble: 510 × 7
cod_regim nome_regim ano Urbana Rural Total pct_urb
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 110001 Porto Velho 2022 494869 57375 552244 89.6
2 110002 Ariquemes 2022 132299 50729 183028 72.3
3 110003 Jaru 2022 64889 39706 104595 62.0
4 110004 Ji-Paraná 2022 209556 79755 289311 72.4
5 110005 Cacoal 2022 208836 83625 292461 71.4
6 110006 Vilhena 2022 127611 23426 151037 84.5
7 120001 Rio Branco 2022 389623 63720 453343 85.9
8 120002 Brasiléia 2022 44719 26271 70990 63.0
9 120003 Sena Madureira 2022 36506 23074 59580 61.3
10 120004 Cruzeiro do Sul 2022 96652 56466 153118 63.1
# ℹ 500 more rows
# ℹ Use `print(n = ...)` to see more rows4.4.7 arrange()
A função arrange() altera a ordem que os registros (linhas) são armazenados (ou exibidas).
Vamos usar a função arrange() para ordenar os dados populacao pelo percentual de população urbana, do menor para o maior.
populacao |>
arrange(pct_urb)
# A tibble: 510 × 7
cod_regim nome_regim ano Urbana Rural Total pct_urb
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 140002 Pacaraima 2022 13630 45038 58668 23.2
2 290026 Euclides da Cunha 2022 78469 109386 187855 41.8
3 210006 Barreirinhas 2022 49711 68923 118634 41.9
4 210007 Tutóia - Araioses 2022 73063 99512 172575 42.3
5 150020 Breves 2022 173837 231453 405290 42.9
6 230017 Acaraú 2022 98360 123339 221699 44.4
7 220010 Paulistana 2022 34849 43041 77890 44.7
8 220013 São Raimundo Nonato 2022 51690 60991 112681 45.9
9 210005 Viana 2022 114078 130074 244152 46.7
10 220005 Barras 2022 43510 49478 92988 46.8
# ℹ 500 more rows
# ℹ Use `print(n = ...)` to see more rowsPodemos fazer o inverso da seguinte maneira:
populacao |>
arrange(desc(pct_urb))
# A tibble: 510 × 7
cod_regim nome_regim ano Urbana Rural Total pct_urb
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 330001 Rio de Janeiro 2022 11679151 28677 11707828 99.8
2 350001 São Paulo 2022 20492117 152219 20644336 99.3
3 350002 Santos 2022 1805518 13514 1819032 99.3
4 310001 Belo Horizonte 2022 4970615 48341 5018956 99.0
5 350038 Campinas 2022 2992359 36944 3029303 98.8
6 520001 Goiânia 2022 2490402 31480 2521882 98.8
7 270001 Maceió 2022 1241573 18145 1259718 98.6
8 260001 Recife 2022 3701809 61380 3763189 98.4
9 320001 Vitória 2022 1897827 32139 1929966 98.3
10 330013 Cabo Frio 2022 544206 9218 553424 98.3
# ℹ 500 more rows
# ℹ Use `print(n = ...)` to see more rows4.4.8 Juntando tabelas: os diferentes joins
Uma das tarefas que necessitamos com frequência ao gerenciamos dados é unir diferentes tabelas.
O tidyverse possui em seu pacote dplyr diversas funções para fazer a união de tibbles ou data.frames. São elas:
| Função | Descrição | Imagem |
|---|---|---|
| inner_join(X,Y) | Retorna todas as linhas em X que têm correspondência em Y. Caso haja mais de uma correspondência, todas as combinações são retornadas. | 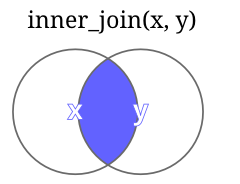 |
| left_join(X,Y) | Retorna toda a tabela X e mais as colunas da tabela Y que têm correspondência em X. Caso haja mais de uma correspondência, todas as combinações são retornadas. | 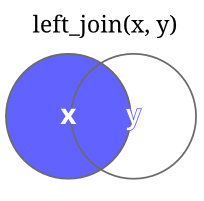 |
| anti_join(X,Y) | Retorna todas as linhas de X que NÃO têm correspondência em Y. | 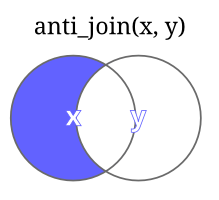 |
| full_join(X,Y) | Retorna todas as linhas de X e de Y. As que não tem correspondência recebem NA. | 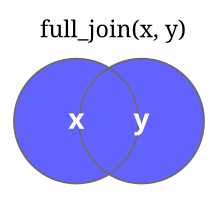 |
| semi_join(X,Y) | Retorna somente as linhas de X onde existem correspondente em Y. Não duplica o número de linhas de X. | 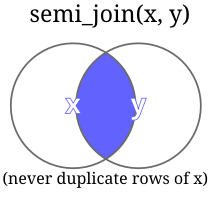 |
| right_join(X,Y) | Retorna todas as linhas de Y e mais as colunas de X que têm correspondência em Y. | 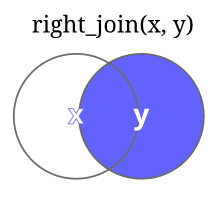 |
Vamos criar algumas estruturas de dados para que possamos ilustrar esses exemplos.
A primeira será uma tabela de alunos:
library(tidyverse)
alunos <- tribble (
~MAT, ~TURMA, ~CURSO, ~NOME, ~SEXO, ~DT_NASC, ~END,
"30211","01/2017", "MSC", "Luiz Correia Cunha", "M","11/12/1979","Rua Solimões, 1406 - Goiania/GO",
"30432","01/2017", "MSC", "Maria Ribeiro Silva","F","29/10/1983","Super Quadra 301 Conjunto 02, 601 - BSB/DF",
"20345","02/2016", "PHD", "Otávio José Rocha","M","26/06/1989","Rua Treze, 179 - Caraguatatuba/SP",
"30131","01/2016", "MSC", "Alice Oliveira Araujo","F", "20/04/1987","Rua Curuçá, 309 - Rio de Janeiro/RJ",
"30225","01/2017", "MSC", "Giovanna Cavalcanti Oliveira", "F" , "14/01/1988", "Rua José da Silva, 47 - Arapiraca/AL",
"20456","01/2015", "PHD", "Vinícius Pereira Dias","M","29/06/1980","Rua Jack Fadel, 1308 - Curitiba/PR",
"20765","02/2015", "PHD", "Maria Melo Souza","F","10/10/1974","Rua São Gonçalo, 752 - Itaguaí/RJ",
"30543","01/2017", "PHD", "Gabriela Carvalho Costa","F","20/09/1976","Largo da Penha, 78 - Rio de Janeiro/RJ",
"30156","02/2016", "MSC", "Kauan Pinto Araujo","M","12/02/1981","Alameda Batatais, 1343 - Rio de Janeiro/RJ",
"30082","01/2016", "MSC", "Rebeca Barbosa Ferreira","F", "22/12/1990","Rua Paulino Giorgis, 1161 - Bagé/RS",
"30567","01/2017", "MSC", "Alonso Mariano da Costa", "M", "17/08/1992", "Rua Marques de Olinda, 786, Rio de Janeiro/RJ"
)A tabela seguinte será disciplinas:
disciplinas <- tribble(
~DISCIPLINA, ~CODIS,
"Curso Básico de R", "ENSP.82.121.2" ,
"Dinâmica Socioambiental e Doenças Transmissíveis", "ENSP.85.100.1",
"Epidemiologia - Conceitos e Métodos I", "ENSP.81.100.1" ,
"Epistemologia, História e Filosofia da Ciência", "ENSP.80.113.1",
"Estatística Aplicada à Epidemiologia", "ENSP.82.104.2",
"Matemática Aplicada I", "ENSP.82.100.1" ,
"Seminários Avançados de Doutorado I", "ENSP.80.104.1",
"Tópicos em Saúde Pública", "ENSP.80.103.1",
"Epidemiologia - Conceitos e Métodos II", "ENSP.81.101.1",
"Introdução a Data Science Aplicada à Epidemiologia", "ENSP.82.137.1",
"Modelos Estatísticos I", "ENSP.82.105.2",
"Modelos Estatísticos II", "ENSP.82.107.2",
"Seminários Avançados de Doutorado", "ENSP.80.119.1",
"Seminários Avançados de Mestrado", "ENSP.80.122.1"
)E, por fim, a tabela notas:
notas <- tribble(
~CODIS, ~MAT, ~NOTA,
"ENSP.82.105.2", "30211", "A",
"ENSP.82.105.2", "30432", "A",
"ENSP.82.105.2", "30131", "C",
"ENSP.82.105.2", "30225", "B",
"ENSP.82.105.2", "30543", "A",
"ENSP.80.119.1", "20345", "B",
"ENSP.80.119.1", "20456", "B",
"ENSP.80.119.1", "30543", "A",
"ENSP.82.107.2", "30156", "A",
"ENSP.82.107.2", "30082", "A",
"ENSP.82.107.2", "30131", "B",
"ENSP.80.122.1", "30131", "A",
"ENSP.80.122.1", "30211", "C",
"ENSP.80.122.1", "30432", "B",
"ENSP.82.137.1", "30543", "A",
"ENSP.82.121.2", "30432", "A",
"ENSP.85.100.1", "30543", "B",
"ENSP.82.121.2", "30131", "C",
"ENSP.82.121.2", "30225", "A",
"ENSP.82.121.2", "20456", "B",
"ENSP.82.121.2", "30156", "D",
"ENSP.82.121.2", "30211", "B"
)Crie as 3 tabelas e as inspecione para ver se todas estão corretas. Agora vamos fazer algumas relacionamentos com elas.
Primeiro, vamos fazer juntar as notas à tabela de alunos com left_join():
alunos %>%
left_join(notas)
Joining with `by = join_by(MAT)`
# A tibble: 24 × 9
MAT TURMA CURSO NOME SEXO DT_NASC END CODIS NOTA
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 30211 01/2017 MSC Luiz Correia Cunha M 11/12/1979 Rua Solimões, 1406 - Goiania/GO ENSP.82.105.2 A
2 30211 01/2017 MSC Luiz Correia Cunha M 11/12/1979 Rua Solimões, 1406 - Goiania/GO ENSP.80.122.1 C
3 30211 01/2017 MSC Luiz Correia Cunha M 11/12/1979 Rua Solimões, 1406 - Goiania/GO ENSP.82.121.2 B
4 30432 01/2017 MSC Maria Ribeiro Silva F 29/10/1983 Super Quadra 301 Conjunto 02, 601 - BSB/DF ENSP.82.105.2 A
5 30432 01/2017 MSC Maria Ribeiro Silva F 29/10/1983 Super Quadra 301 Conjunto 02, 601 - BSB/DF ENSP.80.122.1 B
6 30432 01/2017 MSC Maria Ribeiro Silva F 29/10/1983 Super Quadra 301 Conjunto 02, 601 - BSB/DF ENSP.82.121.2 A
7 20345 02/2016 PHD Otávio José Rocha M 26/06/1989 Rua Treze, 179 - Caraguatatuba/SP ENSP.80.119.1 B
8 30131 01/2016 MSC Alice Oliveira Araujo F 20/04/1987 Rua Curuçá, 309 - Rio de Janeiro/RJ ENSP.82.105.2 C
9 30131 01/2016 MSC Alice Oliveira Araujo F 20/04/1987 Rua Curuçá, 309 - Rio de Janeiro/RJ ENSP.82.107.2 B
10 30131 01/2016 MSC Alice Oliveira Araujo F 20/04/1987 Rua Curuçá, 309 - Rio de Janeiro/RJ ENSP.80.122.1 A
# ℹ 14 more rows
# ℹ Use `print(n = ...)` to see more rowsRepare que apareceu a mensagem “Joining with `by = join_by(MAT)`”. Ou seja, a função detectou automaticamente a variável MAT nos dois objetos e determinou que esta seria a chave para a união.
Algumas vezes é necessário especificar a chave usada para o join, mas mesmo quando não necessário, é boa prática especificar para que fique corretamente registrado no código o que foi feito.
alunos %>%
left_join(notas, join_by(MAT))A especificação da chave também pode ser feita da seguinte maneira:
alunos %>%
left_join(notas, by = "MAT")A primeira forma tem sido preferida já acaba permitindo um código mais limpo e mais fácil de ler::
by = "x"é equivalente àjoin_by(x),by = c("a" = "x")é equivalente àjoin_by(a == x).
O segundo caso é quando a variável chave possui nomes diferentes nos dois bancos de dados. Vamos renomear a variável MAT no objeto alunos e tentar juntar ao objeto notas pra ver o que acontece:
alunos %>%
rename(MATRICULA = MAT) %>%
left_join(notas)
Error in `left_join()`:
! `by` must be supplied when `x` and `y` have no common variables.
ℹ Use `cross_join()` to perform a cross-join.
Run `rlang::last_trace()` to see where the error occurred.A função não mais conseguiu identificar a variável que funciona como chave para a união dos dois objetos. A mensagem de erro nos avisa que precisamos especificar o by:
alunos %>%
rename(MATRICULA = MAT) %>%
left_join(notas, join_by(MATRICULA == MAT))
# A tibble: 24 × 9
MATRICULA TURMA CURSO NOME SEXO DT_NASC END CODIS NOTA
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 30211 01/2017 MSC Luiz Correia Cunha M 11/12/1979 Rua Solimões, 1406 - Goiania/GO ENSP.82.105.2 A
2 30211 01/2017 MSC Luiz Correia Cunha M 11/12/1979 Rua Solimões, 1406 - Goiania/GO ENSP.80.122.1 C
3 30211 01/2017 MSC Luiz Correia Cunha M 11/12/1979 Rua Solimões, 1406 - Goiania/GO ENSP.82.121.2 B
4 30432 01/2017 MSC Maria Ribeiro Silva F 29/10/1983 Super Quadra 301 Conjunto 02, 601 - BSB/DF ENSP.82.105.2 A
5 30432 01/2017 MSC Maria Ribeiro Silva F 29/10/1983 Super Quadra 301 Conjunto 02, 601 - BSB/DF ENSP.80.122.1 B
6 30432 01/2017 MSC Maria Ribeiro Silva F 29/10/1983 Super Quadra 301 Conjunto 02, 601 - BSB/DF ENSP.82.121.2 A
7 20345 02/2016 PHD Otávio José Rocha M 26/06/1989 Rua Treze, 179 - Caraguatatuba/SP ENSP.80.119.1 B
8 30131 01/2016 MSC Alice Oliveira Araujo F 20/04/1987 Rua Curuçá, 309 - Rio de Janeiro/RJ ENSP.82.105.2 C
9 30131 01/2016 MSC Alice Oliveira Araujo F 20/04/1987 Rua Curuçá, 309 - Rio de Janeiro/RJ ENSP.82.107.2 B
10 30131 01/2016 MSC Alice Oliveira Araujo F 20/04/1987 Rua Curuçá, 309 - Rio de Janeiro/RJ ENSP.80.122.1 A
# ℹ 14 more rows
# ℹ Use `print(n = ...)` to see more rowsPodemos unir mais de um objeto:
alunos %>%
left_join(notas, by = join_by(MAT)) %>%
left_join(disciplinas, by = join_by(CODIS))Repare que para o segundo join a variável chave é diferente, pois é uma união a partir do código da disciplina.
Como você faria para saber quais alunos não tem nota com apenas uma função?
Volte à tabela com os diferentes tipos de join para ajudar!
…
Aqui está a solução:
alunos %>%
anti_join(notas, by = join_by(MAT))
# A tibble: 2 × 7
MAT TURMA CURSO NOME SEXO DT_NASC END
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 20765 02/2015 PHD Maria Melo Souza F 10/10/1974 Rua São Gonçalo, 752 - Itaguaí/RJ
2 30567 01/2017 MSC Alonso Mariano da Costa M 17/08/1992 Rua Marques de Olinda, 786, Rio de Janeiro/RJPerceba que o anti_join() fez um filtro nos dados. Por isso, tanto a função anti_join() quanto a semi_join() são classificadas como filter-joins, por realizarem uniões de filtragem. As demais funções (left_join(), full_join(), right_join(), inner_join()) são, por sua vez, mutate-joins, por modificarem os dados adicionando colunas de y em x.
Podemos combinar outras funções do dplyr com as funções de join.
Como podemos fazer uma tabela em ordem alfabética da turma 01/2017 de mestrado contendo matrícula, nome do aluno, código e nome da disciplina, e nota (nesta ordem)?
…
Uma solução possível é:
alunos %>%
filter(TURMA == "01/2017" & CURSO == "MSC") %>%
select(MAT:NOME) %>%
left_join(notas, join_by(MAT)) %>%
left_join(disciplinas, join_by(CODIS)) %>%
select(MAT, NOME, CODIS, DISCIPLINA, NOTA) %>%
arrange(NOME)
# A tibble: 9 × 5
MAT NOME CODIS DISCIPLINA NOTA
<chr> <chr> <chr> <chr> <chr>
1 30567 Alonso Mariano da Costa NA NA NA
2 30225 Giovanna Cavalcanti Oliveira ENSP.82.105.2 Modelos Estatísticos I B
3 30225 Giovanna Cavalcanti Oliveira ENSP.82.121.2 Curso Básico de R A
4 30211 Luiz Correia Cunha ENSP.82.105.2 Modelos Estatísticos I A
5 30211 Luiz Correia Cunha ENSP.80.122.1 Seminários Avançados de Mestrado C
6 30211 Luiz Correia Cunha ENSP.82.121.2 Curso Básico de R B
7 30432 Maria Ribeiro Silva ENSP.82.105.2 Modelos Estatísticos I A
8 30432 Maria Ribeiro Silva ENSP.80.122.1 Seminários Avançados de Mestrado B
9 30432 Maria Ribeiro Silva ENSP.82.121.2 Curso Básico de R A O que acontece se fizermos o seguinte?
notas %>%
left_join(disciplinas, join_by(CODIS)) %>%
left_join(alunos %>%
select(MAT:NOME),
join_by(MAT)) %>%
filter(TURMA == "01/2017" & CURSO == "MSC") %>%
select(MAT, NOME, CODIS, DISCIPLINA, NOTA) %>%
arrange(NOME)Qual foi a diferença?
Com o que aprendeu, tente realizar as tarefas abaixo.
Identifique o nome e código das disciplinas que não possuem alunos matriculados.
Liste as disciplinas e alunos com nenhum conceito abaixo de B.
4.4.9 union() e union_all()
A função union() une linhas de diferentes tabelas com a mesma estrutura, excluindo linhas duplicadas.
df1 <- tibble(id = c(1, 2, 3),
valor = c("A", "B", "C"))
df2 <- tibble(id = c(2, 3, 4),
valor = c("B", "C", "D"))
df1 %>%
union(df2)
# A tibble: 4 × 2
id valor
<dbl> <chr>
1 1 A
2 2 B
3 3 C
4 4 D A variante dessa função de nome union_all() irá manter as linhas duplicadas.
df1 %>%
union_all(df2)
id valor
<dbl> <chr>
1 1 A
2 2 B
3 3 C
4 2 B
5 3 C
6 4 D 4.4.10 intersect() e set_diff()
A função intersect() mostra as linhas em comum entre duas tabelas, ao passo que a função setdiff() faz exatamente o oposto, retornando as linhas diferentes.
df1 %>%
intersect(df2)
# A tibble: 2 × 2
id valor
<dbl> <chr>
1 2 B
2 3 C
df1 %>%
setdiff(df2)
# A tibble: 1 × 2
id valor
<dbl> <chr>
1 1 A
df2 %>%
setdiff(df1)
# A tibble: 1 × 2
id valor
<dbl> <chr>
1 4 D 4.4.11 bind_rows()
A função bind_rows() é equivalente à rbind() do módulo base e serve para empilhar linhas de dois ou mais objetos mesmo que tenham estruturas diferentes (diferente das funções union() e union_all()). bind_rows() vai juntar tabelas linha a linha, mantendo duplicatas, e se houver colunas diferentes entre as tabelas, os valores das colunas que não existem em uma tabela são preenchidas com NA.
Veja o exemplo abaixo:
df1 %>%
bind_rows(df2)
# A tibble: 6 × 2
id valor
<dbl> <chr>
1 1 A
2 2 B
3 3 C
4 2 B
5 3 C
6 4 D O resultado foi o mesmo utilizando union_all(). Por que?
Agora com estruturas diferentes então:
df2b <- tibble(id = c(2,3,4),
novo = c("X","Y","Z"))
df1 %>%
bind_rows(df2b)
# A tibble: 6 × 3
id valor novo
<dbl> <chr> <chr>
1 1 A NA
2 2 B NA
3 3 C NA
4 2 NA X
5 3 NA Y
6 4 NA Z O que acontece quando se tenta juntar as linhas de df1 com df2b com a função union_all()?
4.4.12 bind_cols()
A função bind_cols() cola colunas lado a lado de um ou mais objetos. Diferente dos joins (como left_join()), essa junção de colunas ocorre sem considerar uma chave e os objetos tem que ter o mesmo número de linhas.
df3 <- tibble(y = c(10, 20, 30))
bind_cols(df1, df3)
# A tibble: 3 × 3
id valor y
<dbl> <chr> <dbl>
1 1 A 10
2 2 B 20
3 3 C 304.4.13 Demais funções úteis
Existem ainda outras funções bastante úteis no pacote dplyr.
Vamos pegar os dados de algumas variavéis do Rio de Janeiro por bairros no ano de 2016 (Freitas L et al., 2021) para servir como exemplo:
url <- "https://raw.githubusercontent.com/laispfreitas/ICAR_chikungunya/refs/heads/master/covariates_rio.csv"
rio <- read_csv(url)
rio
# A tibble: 160 × 5
neigh_name neigh_code population sdi green_area
<chr> <dbl> <dbl> <dbl> <dbl>
1 SAUDE 1 2749 0.583 0.0147
2 GAMBOA 2 13108 0.559 0.0215
3 SANTO CRISTO 3 12330 0.569 0.00876
4 CAJU 4 20477 0.554 0.0175
5 CENTRO 5 41142 0.643 0.00274
6 CATUMBI 6 12556 0.58 0.0942
7 RIO COMPRIDO 7 43764 0.605 0.357
8 CIDADE NOVA 8 5466 0.594 0
9 ESTACIO 9 17189 0.586 0.0220
10 SAO CRISTOVAO 10 26510 0.615 0.0214
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowsFunções auxiliares e avançadas do dplyr:
slice()→ selecionar linhas por posição
rio %>%
slice(1:5)
# A tibble: 5 × 5
neigh_name neigh_code population sdi green_area
<chr> <dbl> <dbl> <dbl> <dbl>
1 SAUDE 1 2749 0.583 0.0147
2 GAMBOA 2 13108 0.559 0.0215
3 SANTO CRISTO 3 12330 0.569 0.00876
4 CAJU 4 20477 0.554 0.0175
5 CENTRO 5 41142 0.643 0.00274
rio %>%
slice(-1)
# A tibble: 159 × 5
neigh_name neigh_code population sdi green_area
<chr> <dbl> <dbl> <dbl> <dbl>
1 GAMBOA 2 13108 0.559 0.0215
2 SANTO CRISTO 3 12330 0.569 0.00876
3 CAJU 4 20477 0.554 0.0175
4 CENTRO 5 41142 0.643 0.00274
5 CATUMBI 6 12556 0.58 0.0942
6 RIO COMPRIDO 7 43764 0.605 0.357
7 CIDADE NOVA 8 5466 0.594 0
8 ESTACIO 9 17189 0.586 0.0220
9 SAO CRISTOVAO 10 26510 0.615 0.0214
10 MANGUEIRA 11 17835 0.537 0.187
# ℹ 149 more rows
# ℹ Use `print(n = ...)` to see morcount()→ contar ocorrências de combinações
rio %>%
count(neigh_name)
# A tibble: 160 × 2
neigh_name n
<chr> <int>
1 ABOLICAO 1
2 ACARI 1
3 AGUA SANTA 1
4 ALTO DA BOA VISTA 1
5 ANCHIETA 1
6 ANDARAI 1
7 ANIL 1
8 BANCARIOS 1
9 BANGU 1
10 BARRA DA TIJUCA 1
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowscase_when()→ recodificação com várias condições
rio %>%
mutate(
green_cat = case_when(
green_area < 0.1 ~ "baixa",
green_area < 0.5 ~ "média",
TRUE ~ "alta"
)
)
# A tibble: 160 × 6
neigh_name neigh_code population sdi green_area green_cat
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 SAUDE 1 2749 0.583 0.0147 baixa
2 GAMBOA 2 13108 0.559 0.0215 baixa
3 SANTO CRISTO 3 12330 0.569 0.00876 baixa
4 CAJU 4 20477 0.554 0.0175 baixa
5 CENTRO 5 41142 0.643 0.00274 baixa
6 CATUMBI 6 12556 0.58 0.0942 baixa
7 RIO COMPRIDO 7 43764 0.605 0.357 média
8 CIDADE NOVA 8 5466 0.594 0 baixa
9 ESTACIO 9 17189 0.586 0.0220 baixa
10 SAO CRISTOVAO 10 26510 0.615 0.0214 baixa
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowsif_else()→ condição simples
rio %>%
mutate(pouco_verde = if_else(green_area < 0.1, TRUE, FALSE))
# A tibble: 160 × 6
neigh_name neigh_code population sdi green_area pouco_verde
<chr> <dbl> <dbl> <dbl> <dbl> <lgl>
1 SAUDE 1 2749 0.583 0.0147 TRUE
2 GAMBOA 2 13108 0.559 0.0215 TRUE
3 SANTO CRISTO 3 12330 0.569 0.00876 TRUE
4 CAJU 4 20477 0.554 0.0175 TRUE
5 CENTRO 5 41142 0.643 0.00274 TRUE
6 CATUMBI 6 12556 0.58 0.0942 TRUE
7 RIO COMPRIDO 7 43764 0.605 0.357 FALSE
8 CIDADE NOVA 8 5466 0.594 0 TRUE
9 ESTACIO 9 17189 0.586 0.0220 TRUE
10 SAO CRISTOVAO 10 26510 0.615 0.0214 TRUE
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowsn()→ contar observações (dentro desummarise())
rio %>%
summarise(total_linhas = n())
# A tibble: 1 × 1
total_linhas
<int>
1 160n_distinct()→ contar valores distintos
rio %>%
summarise(bairros_unicos = n_distinct(neigh_code))
# A tibble: 1 × 1
bairros_unicos
<int>
1 160pull()→ extrair uma coluna como vetor
nomes_bairros <- rio %>%
pull(neigh_name)
nomes_bairros[1:20]
[1] "SAUDE" "GAMBOA" "SANTO CRISTO" "CAJU" "CENTRO" "CATUMBI" "RIO COMPRIDO"
[8] "CIDADE NOVA" "ESTACIO" "SAO CRISTOVAO" "MANGUEIRA" "BENFICA" "PAQUETA" "SANTA TERESA"
[15] "FLAMENGO" "GLORIA" "LARANJEIRAS" "CATETE" "COSME VELHO" "BOTAFOGO" across()→ aplicar função a várias colunas de uma vez
rio %>%
summarise(across(population:green_area, \(x) mean(x, na.rm = TRUE)))
# A tibble: 1 × 3
population sdi green_area
<dbl> <dbl> <dbl>
1 39503. 0.608 0.213Funções auxiliares para seleção de colunas:
where()→ selecionar por tipo
rio %>%
select(where(is.numeric))
# A tibble: 160 × 4
neigh_code population sdi green_area
<dbl> <dbl> <dbl> <dbl>
1 1 2749 0.583 0.0147
2 2 13108 0.559 0.0215
3 3 12330 0.569 0.00876
4 4 20477 0.554 0.0175
5 5 41142 0.643 0.00274
6 6 12556 0.58 0.0942
7 7 43764 0.605 0.357
8 8 5466 0.594 0
9 9 17189 0.586 0.0220
10 10 26510 0.615 0.0214
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowsstarts_with()→ nomes de variáveis que começam com um padrão
rio %>%
select(starts_with("neigh"))
# A tibble: 160 × 2
neigh_name neigh_code
<chr> <dbl>
1 SAUDE 1
2 GAMBOA 2
3 SANTO CRISTO 3
4 CAJU 4
5 CENTRO 5
6 CATUMBI 6
7 RIO COMPRIDO 7
8 CIDADE NOVA 8
9 ESTACIO 9
10 SAO CRISTOVAO 10
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowsends_with()→ nomes de variáveis que terminam com um padrão
rio %>%
select(ends_with("area"))
# A tibble: 160 × 1
green_area
<dbl>
1 0.0147
2 0.0215
3 0.00876
4 0.0175
5 0.00274
6 0.0942
7 0.357
8 0
9 0.0220
10 0.0214
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowscontains()→ nomes que contêm um padrão
rio %>%
select(contains("pop"))
# A tibble: 160 × 1
population
<dbl>
1 2749
2 13108
3 12330
4 20477
5 41142
6 12556
7 43764
8 5466
9 17189
10 26510
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowsmatches()→ seleção por regex
rio %>%
select(matches("^n")) # colunas que começam com 'n'
# A tibble: 160 × 2
neigh_name neigh_code
<chr> <dbl>
1 SAUDE 1
2 GAMBOA 2
3 SANTO CRISTO 3
4 CAJU 4
5 CENTRO 5
6 CATUMBI 6
7 RIO COMPRIDO 7
8 CIDADE NOVA 8
9 ESTACIO 9
10 SAO CRISTOVAO 10
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rows4.5 Manipulando strings com stringr

O pacote stringr possui diversas funções que permitem a manipulação de strings (texto) de uma forma diferente do R base. Todas as funções começam com str_, e possuem diversos usos, desde detecção de padrões até a transformação e padronização de strings.
Para saber mais sobre o stringr, clique AQUI.
As funções do stringr podem ser divididas em grupos.
ATENÇÃO! Todas as funções do stringr são case sensitive (sensível a maiúsculas e minúsculas).
4.5.1 Detecção de padrões
Voltemos ao vetor nomes_bairros que criamos a partir da tabela rio.
Vamos usar a função str_detect() para detectar todos os bairros que contém “JARDIM” no nome:
str_detect(nomes_bairros, "JARDIM")
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[20] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[39] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[58] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[77] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[96] FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[115] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[134] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[153] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSEA função str_detect() retorna se cada um dos elementos do vetor possui o padrão (que pode ser uma regular expression).
Podemos alinhar com a função filter() para filtrar apenas os bairros que contém “JARDIM” no nome na tabela rio:
rio %>%
filter(str_detect(neigh_name, "JARDIM"))
# A tibble: 5 × 5
neigh_name neigh_code population sdi green_area
<chr> <dbl> <dbl> <dbl> <dbl>
1 JARDIM BOTANICO 28 18009 0.767 0.375
2 JARDIM AMERICA 49 25226 0.587 0.0173
3 JARDIM GUANABARA 99 32213 0.72 0.0828
4 JARDIM CARIOCA 100 24848 0.61 0.00352
5 JARDIM SULACAP 137 13062 0.641 0.673 A função str_which() retorna qual a posição das strings que possuem o padrão informado:
str_which(nomes_bairros, "JARDIM")
[1] 28 49 99 100 137Podemos usar str_subset() para obter um vetor com os nomes dos municípios que possuem um certo padrão, por exemplo, que possuem “JARDIM” em seu nome:
str_subset(rio$neigh_name, "JARDIM"))
[1] "JARDIM BOTANICO" "JARDIM AMERICA" "JARDIM GUANABARA" "JARDIM CARIOCA" "JARDIM SULACAP"4.5.2 Localização e extração
Podemos saber a posição da primeira ocorrência com str_locate().
str_locate(nomes_bairros, 'A')
start end
[1,] 2 2
[2,] 2 2
[3,] 2 2
[4,] 2 2
[5,] NA NA
[6,] 2 2
[7,] NA NA
[8,] 4 4
[9,] 4 4
[10,] 2 2
...E se quisermos saber a posição de todas as ocorrências, usamos str_locate_all().
str_locate_all(nomes_bairros, "A")
[[1]]
start end
[1,] 2 2
[[2]]
start end
[1,] 2 2
[2,] 6 6
[[3]]
start end
[1,] 2 2
[[4]]
start end
[1,] 2 2Agora vamos retornar ao objeto aids.longo.
aids.longo
# A tibble: 242,000 × 4
cod_mun_res mun_res ano casos
<chr> <chr> <chr> <dbl>
1 110001 Alta Floresta D'Oeste 1980 0
2 110001 Alta Floresta D'Oeste 1982 0
3 110001 Alta Floresta D'Oeste 1983 0
4 110001 Alta Floresta D'Oeste 1984 0
5 110001 Alta Floresta D'Oeste 1985 0
6 110001 Alta Floresta D'Oeste 1986 0
7 110001 Alta Floresta D'Oeste 1987 0
8 110001 Alta Floresta D'Oeste 1988 0
9 110001 Alta Floresta D'Oeste 1989 0
10 110001 Alta Floresta D'Oeste 1990 0
# ℹ 241,990 more rows
# ℹ Use `print(n = ...)` to see more rowsPodemos usar a str_sub() para criar a variável do código UF da residência, que corresponde aos dois primeiros dígitos de cod_mun_res.
aids.longo %>%
mutate(cod_UF_res = str_sub(cod_mun_res, 1, 2))
# A tibble: 242,000 × 5
cod_mun_res mun_res ano casos cod_UF_res
<chr> <chr> <chr> <dbl> <chr>
1 110001 Alta Floresta D'Oeste 1980 0 11
2 110001 Alta Floresta D'Oeste 1982 0 11
3 110001 Alta Floresta D'Oeste 1983 0 11
4 110001 Alta Floresta D'Oeste 1984 0 11
5 110001 Alta Floresta D'Oeste 1985 0 11
6 110001 Alta Floresta D'Oeste 1986 0 11
7 110001 Alta Floresta D'Oeste 1987 0 11
8 110001 Alta Floresta D'Oeste 1988 0 11
9 110001 Alta Floresta D'Oeste 1989 0 11
10 110001 Alta Floresta D'Oeste 1990 0 11
# ℹ 241,990 more rows
# ℹ Use `print(n = ...)` to see more rowsA função str_extract() extrai o trecho da string que corresponde ao padrão da regex. No exemplo abaixo, queremos extrair apenas os números das strings:
x <- c("ID:123", "ID:456")
str_extract(x, "\\d+")
[1] "123" "456"A função str_match() serve para extrair o trecho completo e os grupos capturados (que ficam entre parênteses):
str_match(x, "ID:(\\d+)")
[,1] [,2]
[1,] "ID:123" "123"
[2,] "ID:456" "456"Outro exemplo:
y <- c("RJ-2020", "MG-2021")
str_match(y, "([A-Za-z]+)-(\\d+)")
[,1] [,2] [,3]
[1,] "RJ-2020" "RJ" "2020"
[2,] "MG-2021" "MG" "2021"4.5.3 Medir strings
A str_count() conta o número de vezes que um padrão é encontrado em cada elemento string. Abaixo, um exemplo contando quantas vogais nos nomes dos bairros do Rio de Janeiro:
str_count(nomes_bairros, "[AEIOU]")
[1] 3 3 4 2 2 3 5 5 4 6 5 3 4 5 3 3 5 3 4 4 4 2 2 5 4 2 3 6 3 3 5 7 3 7 4 5 4 3 4
[40] 4 2 4 2 5 4 3 6 6 6 6 3 6 4 4 7 5 8 2 5 4 5 6 3 5 3 6 5 4 4 5 3 4 7 5 5 3 4 3
[79] 9 4 7 4 5 3 4 5 6 4 6 5 4 2 4 6 8 3 4 5 7 6 3 3 5 4 10 5 4 7 10 5 3 4 4 3 6 2 6
[118] 6 4 11 3 4 3 4 7 2 4 6 3 6 4 10 3 4 5 6 5 6 4 5 2 6 4 4 7 5 2 5 3 4 5 8 8 3 5 8
[157] 2 7 5 4A função str_lenght() retorno o número de caracteres em cada string do vetor (e não o número de elementos do vetor).
str_length(nomes_bairros)
[1] 5 6 12 4 6 7 12 11 7 13 9 7 7 12 8 6 11 6 11 8 7 4 4 10 7 6 5 15 5 7 11 17 6 17 8 11 7 6 10
[40] 10 5 6 5 14 12 8 15 13 14 12 6 14 12 7 17 12 20 5 9 7 12 19 5 15 8 17 10 9 7 8 7 11 19 13 12 5 7 8
[79] 17 10 15 9 9 8 7 13 14 12 13 15 7 5 6 12 17 6 9 9 16 14 4 6 10 6 20 9 8 15 22 11 5 12 12 6 11 4 13
[118] 14 8 23 9 7 6 10 14 3 9 15 7 14 13 24 7 7 12 17 14 16 8 12 5 14 10 12 19 8 6 9 10 8 9 18 18 7 11 18
[157] 4 15 13 84.5.4 Transformação de strings
As funções str_to_lower(), str_to_upper() e str_to_title() transformam os caracteres de strings para todos minúsculos, todos maiúsculos, e capitalizados, respectivamente.
Em rio, os nomes dos bairros estão todos em maiúsculos. Podemos modificar da seguinte maneira:
rio |>
mutate(neigh_name = str_to_title(neigh_name))
# A tibble: 160 × 5
neigh_name neigh_code population sdi green_area
<chr> <dbl> <dbl> <dbl> <dbl>
1 Saude 1 2749 0.583 0.0147
2 Gamboa 2 13108 0.559 0.0215
3 Santo Cristo 3 12330 0.569 0.00876
4 Caju 4 20477 0.554 0.0175
5 Centro 5 41142 0.643 0.00274
6 Catumbi 6 12556 0.58 0.0942
7 Rio Comprido 7 43764 0.605 0.357
8 Cidade Nova 8 5466 0.594 0
9 Estacio 9 17189 0.586 0.0220
10 Sao Cristovao 10 26510 0.615 0.0214
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowsA funções str_replace() e str_replace_all() permitem a substituição de um padrão por outro. Fique atento que a str_replace() altera somente a primeira ocorrência do padrão!
nomes_bairros[1:14]
[1] "SAUDE" "GAMBOA" "SANTO CRISTO" "CAJU" "CENTRO" "CATUMBI" "RIO COMPRIDO"
[8] "CIDADE NOVA" "ESTACIO" "SAO CRISTOVAO" "MANGUEIRA" "BENFICA" "PAQUETA" "SANTA TERESA"
str_replace(nomes_bairros[1:14], "SAO", "SÃO")
[1] "SAUDE" "GAMBOA" "SANTO CRISTO" "CAJU" "CENTRO" "CATUMBI" "RIO COMPRIDO"
[8] "CIDADE NOVA" "ESTACIO" "SÃO CRISTOVAO" "MANGUEIRA" "BENFICA" "PAQUETA" "SANTA TERESA" A função str_pad() serve para “preencher” strings com caracteres extras, até que todas tenham o mesmo comprimento.
Abaixo temos um exemplo onde são incluídos caracteres (por padrão espaços em branco) à esquerda para alcançar um tamanho fixo de string de 14 caracteres.
str_pad(nomes_bairros[1:10], 14, "left")
[1] " SAUDE" " GAMBOA" " SANTO CRISTO" " CAJU" " CENTRO" " CATUMBI" " RIO COMPRIDO"
[8] " CIDADE NOVA" " ESTACIO" " SAO CRISTOVAO"Agora vamos considerar um tamanho de 16 caracteres, preenchendo em ambos os lados com ‘_’:
str_pad(nomes_bairros[1:10], 16, "both", "_")
[1] "_____SAUDE______" "_____GAMBOA_____" "__SANTO CRISTO__" "______CAJU______" "_____CENTRO_____" "____CATUMBI_____"
[7] "__RIO COMPRIDO__" "__CIDADE NOVA___" "____ESTACIO_____" "_SAO CRISTOVAO__"Essa função costuma ser útil para padronizar o tamanho de caracteres de códigos. Por exemplo, em rio há uma variável neigh_code que é numérica e vai de 1 a 160.
rio |> head()
# A tibble: 6 × 5
neigh_name neigh_code population sdi green_area
<chr> <dbl> <dbl> <dbl> <dbl>
1 SAUDE 1 2749 0.583 0.0147
2 GAMBOA 2 13108 0.559 0.0215
3 SANTO CRISTO 3 12330 0.569 0.00876
4 CAJU 4 20477 0.554 0.0175
5 CENTRO 5 41142 0.643 0.00274
6 CATUMBI 6 12556 0.58 0.0942
rio |> tail()
# A tibble: 6 × 5
neigh_name neigh_code population sdi green_area
<chr> <dbl> <dbl> <dbl> <dbl>
1 JACAREZINHO 155 37839 0.534 0.00285
2 COMPLEXO DO ALEMAO 156 69143 0.532 0.119
3 MARE 157 129770 0.547 0.0263
4 PARQUE COLUMBIA 158 9202 0.549 0.0347
5 VASCO DA GAMA 159 15482 0.593 0
6 GERICINO 160 15167 0.545 0.358 Podemos usar str_pad() para preencher com zeros à esquerda para que todos os códigos tenham 3 dígitos:
rio |>
mutate(neigh_code = str_pad(neigh_code, width = 3, pad = "0", side = "left"))
# A tibble: 160 × 5
neigh_name neigh_code population sdi green_area
<chr> <chr> <dbl> <dbl> <dbl>
1 SAUDE 001 2749 0.583 0.0147
2 GAMBOA 002 13108 0.559 0.0215
3 SANTO CRISTO 003 12330 0.569 0.00876
4 CAJU 004 20477 0.554 0.0175
5 CENTRO 005 41142 0.643 0.00274
6 CATUMBI 006 12556 0.58 0.0942
7 RIO COMPRIDO 007 43764 0.605 0.357
8 CIDADE NOVA 008 5466 0.594 0
9 ESTACIO 009 17189 0.586 0.0220
10 SAO CRISTOVAO 010 26510 0.615 0.0214
# ℹ 150 more rows
# ℹ Use `print(n = ...)` to see more rowsA função str_trim() remove espaços em branco extras no início e/ou no final de uma string.
exemplo <- c(" espaço a esquerda",
"espaço a direita ",
" espaço em ambos os lados ",
"sem espaço")
str_trim(exemplo, "both")
[1] "espaço a esquerda" "espaço a direita" "espaço em ambos os lados" "sem espaço" 4.5.5 Divisão e combinação de strings
A função str_c() concatena strings, similar a paste(). Podemos criar uma variável com o nome e ano em aids.longo que pode servir para rótulos, por exemplo.
aids.longo |>
mutate(mun_ano = str_c(mun_res, ano, sep = " - "))
# A tibble: 242,000 × 5
cod_mun_res mun_res ano casos mun_ano
<chr> <chr> <chr> <dbl> <chr>
1 110001 Alta Floresta D'Oeste 1980 0 Alta Floresta D'Oeste - 1980
2 110001 Alta Floresta D'Oeste 1982 0 Alta Floresta D'Oeste - 1982
3 110001 Alta Floresta D'Oeste 1983 0 Alta Floresta D'Oeste - 1983
4 110001 Alta Floresta D'Oeste 1984 0 Alta Floresta D'Oeste - 1984
5 110001 Alta Floresta D'Oeste 1985 0 Alta Floresta D'Oeste - 1985
6 110001 Alta Floresta D'Oeste 1986 0 Alta Floresta D'Oeste - 1986
7 110001 Alta Floresta D'Oeste 1987 0 Alta Floresta D'Oeste - 1987
8 110001 Alta Floresta D'Oeste 1988 0 Alta Floresta D'Oeste - 1988
9 110001 Alta Floresta D'Oeste 1989 0 Alta Floresta D'Oeste - 1989
10 110001 Alta Floresta D'Oeste 1990 0 Alta Floresta D'Oeste - 1990
# ℹ 241,990 more rows
# ℹ Use `print(n = ...)` to see more rowsTemos a função str_split() e suas similares (str_split_1(), str_split_i(), str_split_all()) que dividem a string em um determinado delimitador.
Vejamos o objeto abaixo, sendo um vetor contendo strings de sintomas de 10 pacientes.
sintomas <- c(
"Febre alta, tosse seca, dor de garganta, fadiga",
"Dor de cabeça, congestão nasal, espirros, coriza",
"Dor abdominal, náuseas, vômitos, diarreia",
"Erupção cutânea, coceira, febre baixa, fadiga",
"Dores musculares, febre,falta de ar, tosse produtiva",
"Dor de cabeça, visão turva, rigidez no pescoço, febre",
"Falta de apetite, perda de peso, cansaço, dor abdominal",
"Tosse crônica, falta de ar, chiado no peito, fadiga",
"Dor nas articulações, inchaço, febre baixa, cansaço",
"Dor de cabeça, tontura, zumbido no ouvido"
)Podemos usar str_split() para isolar cada sintoma:
str_split(sintomas, ",")
[[1]]
[1] "Febre alta" " tosse seca" " dor de garganta" " fadiga"
[[2]]
[1] "Dor de cabeça" " congestão nasal" " espirros" " coriza"
[[3]]
[1] "Dor abdominal" " náuseas" " vômitos" " diarreia"
[[4]]
[1] "Erupção cutânea" " coceira" " febre baixa" " fadiga"
[[5]]
[1] "Dores musculares" " febre" "falta de ar" " tosse produtiva"
[[6]]
[1] "Dor de cabeça" " visão turva" " rigidez no pescoço" " febre"
[[7]]
[1] "Falta de apetite" " perda de peso" " cansaço" " dor abdominal"
[[8]]
[1] "Tosse crônica" " falta de ar" " chiado no peito" " fadiga"
[[9]]
[1] "Dor nas articulações" " inchaço" " febre baixa" " cansaço"
[[10]]
[1] "Dor de cabeça" " tontura" " zumbido no ouvido"A função str_glue() permite misturar textos e variáveis:
str_glue(
"Eu me chamo {nome}, ",
"e ano que vem vou fazer {idade + 1} anos.",
nome = "João da Silva",
idade = 40
)
Eu me chamo João da Silva, e ano que vem vou fazer 41 anos.A variação str_glue_data() permite utilizar variáveis dentro de um objeto de dados, ou seja, constrói strings diretamente de colunas de uma tabela.
rio |>
head() |>
str_glue_data("O bairro {neigh_name} tinha {population} habitantes em 2016.")
O bairro SAUDE tinha 2749 habitantes em 2016.
O bairro GAMBOA tinha 13108 habitantes em 2016.
O bairro SANTO CRISTO tinha 12330 habitantes em 2016.
O bairro CAJU tinha 20477 habitantes em 2016.
O bairro CENTRO tinha 41142 habitantes em 2016.
O bairro CATUMBI tinha 12556 habitantes em 2016.4.5.6 Ordenação
Por fim, para ordenar strings temos as funções str_sort() e str_order(). A str_sort() ordena um vetor por ordem alfabética, enquanto str_order() retorna a posição (posto) de cada elemento do vetor.
str_sort(nomes_bairros[1:10])
[1] "CAJU" "CATUMBI" "CENTRO" "CIDADE NOVA" "ESTACIO" "GAMBOA" "RIO COMPRIDO"
[8] "SANTO CRISTO" "SAO CRISTOVAO" "SAUDE"
str_order(nomes_bairros[1:10])
[1] 4 6 5 8 9 2 7 3 10 14.5.7 Exercício
A partir do vetor sintomas e utilizando as funções de stringr:
- Além de separar os sintomas de cada paciente, transforme as strings em todos minúsculos e apague os espaços em branco excedentes.
- Descubra quantos pacientes:
- tiveram febre
- tiveram fadiga ou cansaço
- tiveram dor e febre
- tiveram dor OU febre
- Descubra qual palavra vem depois de febre
- Altere “falta de ar” para “falta_de_ar”
…
Solução:
# quantos tiveram febre
table(str_detect(sintomas, '[Ff]ebre'))
# quantos tiveram fadiga ou cansaço
table(str_detect(sintomas, '[Ff]adiga|cansaço'))
# quantos tiveram dor e febre
table((str_detect(sintomas, '[Dd]or') & str_detect(sintomas,'[Ff]ebre')))
# quantos tiveram dor OU febre
table((str_detect(sintomas, '[Dd]or') | str_detect(sintomas,'[Ff]ebre')))
# qual a palavra vem depois de febre
str_match(sintomas,'[Ff]ebre\\s([a-zA-Z]{1,})')
# mudar falta de ar para falta_de_ar
str_replace_all(sintomas,'falta.*ar','falta_de_ar')4.6 Manipulando datas com lubridate

O lubridate é um pacote que faz parte do tidyverse e simplifica o processo de trabalhar com datas, horas, diferenças entre datas, fuso horário (time zone, TZ) etc.
Existem várias funções, resumidas abaixo:
| Categoria | Função(es) principais | O que faz | Exemplo |
|---|---|---|---|
| Criar datas | ymd(), dmy(), mdy() |
Lê strings em formatos diferentes e converte em datas | ymd("2025-09-06") → “2025-09-06” |
| Data/hora atual | today(), now() |
Data de hoje ou data+hora atuais | today() → “2025-09-06” |
| Extrair componentes | year(), month(), day(), wday() |
Extrai partes da data (ano, mês, dia, dia da semana) | month(today(), label = TRUE) → “Set” |
| Operações com datas | + days(), + months(), + years() |
Soma ou subtrai períodos a datas | ymd("2025-09-06") + days(10) → “2025-09-16” |
| Diferenças/intervalos | interval(), int_length(), as.period() |
Cria intervalos entre datas e calcula duração | interval(ymd("2020-01-01"), ymd("2020-12-31")) → 2020-01-01 UTC–2020-12-31 UTC |
| Durações e períodos | seconds(), minutes(), days(), months() |
Cria objetos de tempo para operações | dez_minutos <- minutes(10) |
Veja um exemplo abaixo da conversão de strings em diferentes formatos para o formato de data usando dmy():
dmy('28/10/2018')
[1] "2018-10-28"
varias <- c('31/01/2010','3-4-2015', '12112011')
dmy(varias)
[1] "2010-01-31" "2015-04-03" "2011-11-12"Note que no exemplo acima todas as datas retornaram no formato ano-mês-dia. Esse formato é chamado formato ISO de datas ou (ISODATE ou ISO 8601 ) formato que é entendido como default por quase todos os computadores e softwares. Assim toda data é armazenado neste formato.
4.6.1 Criando datas
O lubridate tem funções para entender datas em diferentes formatos, inclusive o formato ISO (ymd), o comumente utilizado nos EUA (mdy), e o utilizado no Brasil (dmy). Essas funções tentam identificar o separador e em geral se ajustam bem a diferentes formatações.
Veja abaixo:
ymd("20110604"); mdy("06-04-2011"); dmy("04/06/2011")
[1] "2011-06-04"
[1] "2011-06-04"
[1] "2011-06-04"Perceba que as funções identificam o formato de entrada diferente das datas, mas sempre armazena no formato ISO.
Também é possível entrar datas por extenso, usando o nome do mês como abaixo. No entanto evite usar esse formato!
dmy('21 de agosto de 2008')
[1] "2008-08-21"E importante notar que datas inválidas ou retornam NA :
ymd('2018-02-29')
[1] NA
Warning message:
1 failed to parse.Neste caso, não existiu dia 29 de fevereiro em 2018.
Exercícios
Tente fazer esses exercícios para ajudar a fixar o conteúdo.
- Leia a tabela abaixo:
“https://raw.githubusercontent.com/laispfreitas/curso_CD1/refs/heads/main/infarto_mulheres.csv”
- Separe o código do nome da UF
- Crie uma tabela que tenha
CODUF,UF,ANO,OBITOS - Quais são as UFs com mais de 1000 casos em 2010?
- Crie uma tabela com o número de casos agrupado por ano para todo o Brasil.
- Importe diretamente no
Ra tabela no endereço
“https://raw.githubusercontent.com/laispfreitas/curso_CD1/refs/heads/main/Tabela_Sidra_200.csv”
- Leia os dados e chame a tabela de
tab200. - Normalizar o nome das colunas
- Crie uma nova tabela que deve ter somente as seguintes colunas: nome da UF, ano do censo, sexo, faixa etária e total da população.
- Quais são as UF que tem mais de 5000 mulheres de mais de 90 anos em 2010?
- Retorne somente as faixas etárias entre 20 e 40 anos.
- Deixe o nome das variáveis mais “limpo” removendo a palavra ‘anos’ e substituindo mais por ‘+’.
DICA! Fica aqui um pedaço de função em REGEX para ajudar na limpeza:
gsub('(^[M|H])\\.([0-9]{4})\\.','\\1-\\2-FX_',name(tab200))- Volte ao exemplo da PNAD contínua:
“https://github.com/laispfreitas/curso_CD1/raw/refs/heads/main/PNAD_Continua_2012_2018_Caracteristicas_Gerais_RACA.xlsx”
Agora você deve ter conhecido todas as ferramentas necessárias para transformar essa planilha em dados tidy. Tente em casa! Vai ser importante para praticar, fixar o conteúdo, e encontrar dúvidas.
5 Referências
Freitas LP, Schmidt AM, Cossich W, Cruz OG, Carvalho MS. “Spatio-temporal modelling of the first Chikungunya epidemic in an intra-urban setting: The role of socioeconomic status, environment and temperature”. PLOS Neglected Tropical Diseases, 15(6):e0009537 (2021). https://doi.org/10.1371/journal.pntd.0009537