3 Importando e arrumando dados
3.1 O universo tidy: tidyverse
![]()
O tidyverse revolucionou como os cientistas de dados trabalham usando o R. Ele promove uma filosofia de programação clara, consistente e fácil de aprender, o que o tornou extremamente popular e influente no ecossistema do R e na ciência de dados.
O tidyverse não é um único pacote, mas sim um metapacote, ou seja, uma coleção de pacotes que compartilham uma filosofia comum, formando um framework completo para a ciência de dados em R construído sobre três pilares essenciais:
- a filosofia dos dados arrumados,
- o poder da programação funcional e
- a clareza do operador pipe.
3.1.1 A filosofia dos dados arrumados (tidy data)
No coração do tidyverse está o conceito de tidy data, que defende uma estrutura de dados consistente e universal:
- Cada variável deve ter sua própria coluna.
- Cada observação (ou caso) deve ter sua própria linha.
- Cada unidade de medida deve ter sua própria tabela. (Se você tem dados sobre diferentes tipos de coisas, essas coisas deveriam estar em tabelas separadas.)
Ao organizar os dados dessa forma, o tidyverse garante que todas as suas ferramentas funcionem perfeitamente juntas, simplificando tarefas de manipulação e análise que seriam complexas de outra forma.
3.1.2 O poder da programação funcional
O tidyverse faz uso extensivo de funções que executam uma única tarefa bem definida. Essa abordagem, conhecida como programação funcional, promove a reutilização do código e o torna mais fácil de ler e entender. Em vez de escrever loops complexos, você pode usar funções concisas para aplicar operações a grupos de dados, o que torna seu código mais robusto e menos propenso a erros.
3.1.3 A clareza do operador pipe (%>% ou |> no R 4.1+)
O operador pipe é o que realmente torna o código tidyverse tão intuitivo. Ele permite que você encaminhe o resultado de uma função diretamente para a próxima, criando uma sequência lógica de operações. Isso melhora drasticamente a legibilidade e a manutenção do seu código.
dados |> # Começa com o objeto 'dados'
select(coluna1, coluna2) |> # Usa select() para manter apenas as variáveis coluna1 e coluna2
filter(coluna1 == 'exemplo') # Depois, usa filter() para manter apenas as linhas onde coluna1 == 'exemplo'O operador pipe pega o resultado da linha anterior e passa como primeiro argumento para a função da próxima linha. Assim:
filter(select(dados, coluna1, coluna2), coluna1 == 'exemplo')Mas com o pipe, fica mais legível e mais próximo da lógica humana: “pegue os dados → selecione colunas → filtre as linhas”.
Juntos, esses três pilares criam uma abordagem de ciência de dados que é consistente, poderosa e, acima de tudo, agradável de se trabalhar.
3.1.4 Principais pacotes do tidyverse
readr: Para importação de dados. Oreadroferece uma maneira rápida e robusta de ler arquivos de texto retangular, como CSV e TSV. Ele é mais rápido que as funções base doRe importa os dados diretamente no formato tibble, facilitando a próxima etapa de análise.tibble: Para criar (tibble()) e transformar (as_tibble()) data frames no formato tibble, um formato mais moderno, eficiente e legível. Melhora a exibição dos dados (glimpse()) e mantém tipos de dados consistentes durante operações.dplyr: Para manipulação de dados. Com ele, você pode filtrar linhas (filter()), selecionar colunas (select()), reorganizar dados (arrange()), e resumir dados (summarise()), tudo de maneira clara e legível. Ele substitui a necessidade de escrever códigos complexos e muitas vezes confusos para essas tarefas.tidyr: Para arrumar dados. Este pacote é fundamental para transformar dados “bagunçados” em “arrumados” (tidy data). Funções comopivot_wider()epivot_longer()são essenciais para remodelar tabelas de forma eficiente, uma tarefa comum e muitas vezes difícil.ggplot2: Para visualização de dados. Considerado um dos melhores pacotes de gráficos emR, oggplot2permite criar gráficos impressionantes e personalizados. Ele se baseia na “Gramática dos Gráficos”, onde você constrói seu gráfico camada por camada, dando controle total sobre cada elemento visual.purrr: Para programação funcional. Opurrrajuda a trabalhar com listas e vetores, substituindo loops for por funções mais concisas e expressivas comomap(), tornando seu código mais fácil de ler e menos propenso a erros.stringr: Para manipulação de strings. Este pacote simplifica as operações com texto, como detecção, extração e substituição de padrões.lubridate: Para manipulação de datas e horas de forma mais acessível e eficiente.forcats: Para trabalhar com variáveis categóricas (fatores).
3.1.5 Importância no ecossistema R
Simplificação da manipulação e análises de dados: o
tidyversereduziu drasticamente a complexidade da manipulação e análises de dados noR. Antes dotidyverse, muitas tarefas exigiam códigos mais longos, complexos e difíceis de entender.Melhoria da legibilidade do código: A filosofia do
tidyverseenfatiza a legibilidade do código, o que facilita a colaboração e a manutenção de projetos.Aumento da produtividade: A sintaxe clara e consistente do
tidyversepermite que os usuários realizem tarefas mais rapidamente.Ampliação da acessibilidade: O
tidyversetornou a manipulação e análise de dados emRmais acessíveis para pessoas com diferentes níveis de experiência.Influência em outras bibliotecas: A filosofia do
tidyverseinfluenciou o design de outras bibliotecasR, promovendo a consistência e a clareza.Comunidade ativa: O
tidyversepossui uma comunidade grande e ativa que oferece suporte, compartilha conhecimento e desenvolve novas ferramentas.
3.1.6 A criação do tidyverse
A criação do tidyverse foi um processo contínuo de desenvolvimento, não um evento único. Sua filosofia central sempre foi tornar a manipulação e visualização de dados mais organizada, padronizada e acessível.
O projeto foi iniciado por Hadley Wickham, que, na época, era professor adjunto de estatística na Universidade de Auckland, Nova Zelândia. Ele já estava desenvolvendo pacotes influentes como o ggplot2 para visualização e o dplyr para manipulação de dados.
Mais tarde, Wickham se juntou à empresa RStudio como Cientista chefe. O empresa RStudio posteriormente mudou de nome para Posit e se tornou o lar do tidyverse, apoiando e impulsionando seu desenvolvimento e popularidade na comunidade de R.

Vamos falar mais sobre o tidyverse e ver exemplos ao logo do curso. Algumas vezes vamos usar funções do módulo base do R, pois podem ser mais rápidas ou para ilustrar algum ponto. Lembre-se que para você usar plenamente o R não basta conhecer o tidyverse, também precisa saber usar bem o módulo base!
3.2 Importando dados
A importação de dados é um dos primeiros e mais cruciais passos em qualquer projeto de Ciência de Dados. A qualidade e a eficiência desse processo impactam diretamente a qualidade da análise e dos resultados. Aqui vamos falar da importação de dados, cobrindo principais formatos, funções de leitura, melhores práticas e considerações e observações:
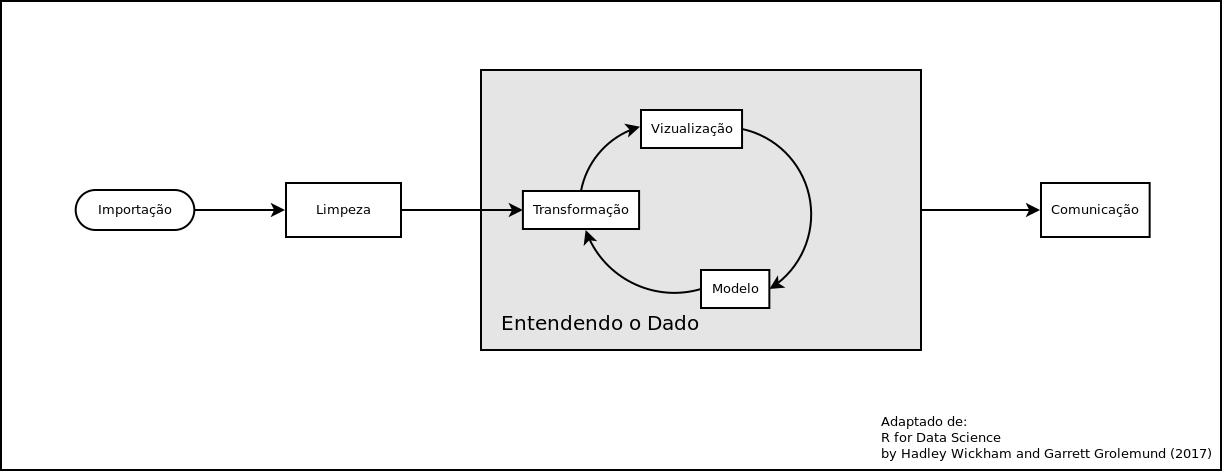
Podemos ver no diagrama abaixo (adaptado de Wickham & Grolemund, 2017), as principais etapas que veremos nesse curso e como tudo começa com a Importação dos dados.
Existem diversas maneiras de importar o dados em R. As principais são:
- Importando de arquivos locais,
- Importação via WEB (APIs, http,ftp, Scraping),
- Acesso a Banco de Dados.
Vamos olhar cada uma delas.
3.2.1 Importando de arquivos locais
Essa é a maneira que todos estão mais acostumados. Em geral se importa um arquivo texto do tipo CSV ou ainda TXT com algum tipo de delimitador, que pode ser espaço,
Comumente se utiliza a função read.table() ou alguma de suas variantes como read.csv() ou read.csv2().
Alguns exemplos:
dados <- read.csv2("planilha.csv")
# ou
dados2 <- read.table("arquivo.txt", header=F, sep=";")3.2.1.1 Benchmarks e cuidados na importação
Um rápido benchmark compara o tempo que cada uma das funções em R (em diferentes pacotes), Python e duckDB demorou para ler um arquivo CSV de 1.5 Gb contendo 3.297.660 linhas e 123 colunas.
| função | pacote | tempo | tam | status |
|---|---|---|---|---|
| read.csv | R base | 28.95s | 1.592.365 | warning |
| read_csv | pandas (python) | 21.40s | 3.254.452 | warning |
| read_csv | readr (tidyverse) | 16.34s | 3.253.190 | warning |
| vroom | vroom | 8.76s | 3.253.190 | warning |
| fread | data.table | 4.28s | — | Erro |
| read_csv | duckDB | 1.87s | 1.620.028 | warning |
Note que nenhuma das funções leu todo o arquivo! A read_csv do pandas, a read_csv do readr e a vroom do pacote de mesmo nome foram as que mais se aproximaram de ler todo o arquivo. A função read.csv do módulo base não só foi a mais lenta como leu cerca da metade do arquivo demorando quase 29 segundos, já a função read_csv do duckDB também leu apenas ~1.6 milhões de registos em menos de 2 segundos.
Observação importante:
Como vimos, nem sempre a importação ocorre da maneira que imaginamos e poucos se dão ao trabalho de ler as mensagens de aviso. o formato CSV, que é apenas um texto separado por um caractere (em geral uma “,” ou “;”), pode facilmente ser comprometido. Basta qualquer linha que tenha um desses caracteres, (por exemplo, um endereço ter um desses delimitadores e não estar entre aspas) para gerar problemas.
Ao exportar um arquivo para CSV lembre-se sempre de configurar para que os campos textos sejam incluídos entre aspas! (Nem sempre resolve, pois pode ter uma ou mais aspas soltas, o que também vai corromper o arquivo CSV).
Também algumas vezes podemos importar algum formato oriundo de outro software, como o SPSS, STATA, SAS, ou até mesmo o extinto formato DBF. No R é necessário chamar o pacote haven, parte do tidyverse, ou a foreign do R base.
No pacote haven você encontra as funções read_sas(), read_sav() e read_dta() para importar respectivamente do SAS, SPSS e STATA.
Por conta da influência dos sistemas do DATASUS na saúde, até hoje temos de lidar com um formato legado chamado DBASE que possui a extensão .DBF ou ainda .DBC (DBase compactado, formato criado pelo DATASUS).
Para importar um DBF com o pacote foreign:
library(foreign)
dados <- read.dbf("datasus.dbf", as.is=TRUE)
## as.is = TRUE não transforma as strings em fatoresJá para o DBC vamos precisar do pacote read.dbc, desenvolvido por Daniela Petruzalek. Não está disponível no CRAN (o repositório oficial do R) no momento deste curso. Por isso, para instalá-lo, você precisará seguir um procedimento alternativo. Vamos instalar do repositório no github da autora e, para isso, precisamos do pacote devtools instalado.
devtools::install_github("danicat/read.dbc")
library(read.dbc)
dados <- read.dbc("datasus.DBC", as.is=TRUE) ## DBC é um DBF mas compactado3.2.2 Importando via WEB
Uma das facilidades do R que é pouco explorada é a possibilidade de ler arquivo através da internet. Algumas das funções podem acessar diretamente e referenciar um link remoto (URL).
Veja o exemplo abaixo:
library(tidyverse)
tab <- read_csv('https://raw.githubusercontent.com/wcota/covid19br/refs/heads/master/cases-brazil-cities.csv')
head(tab)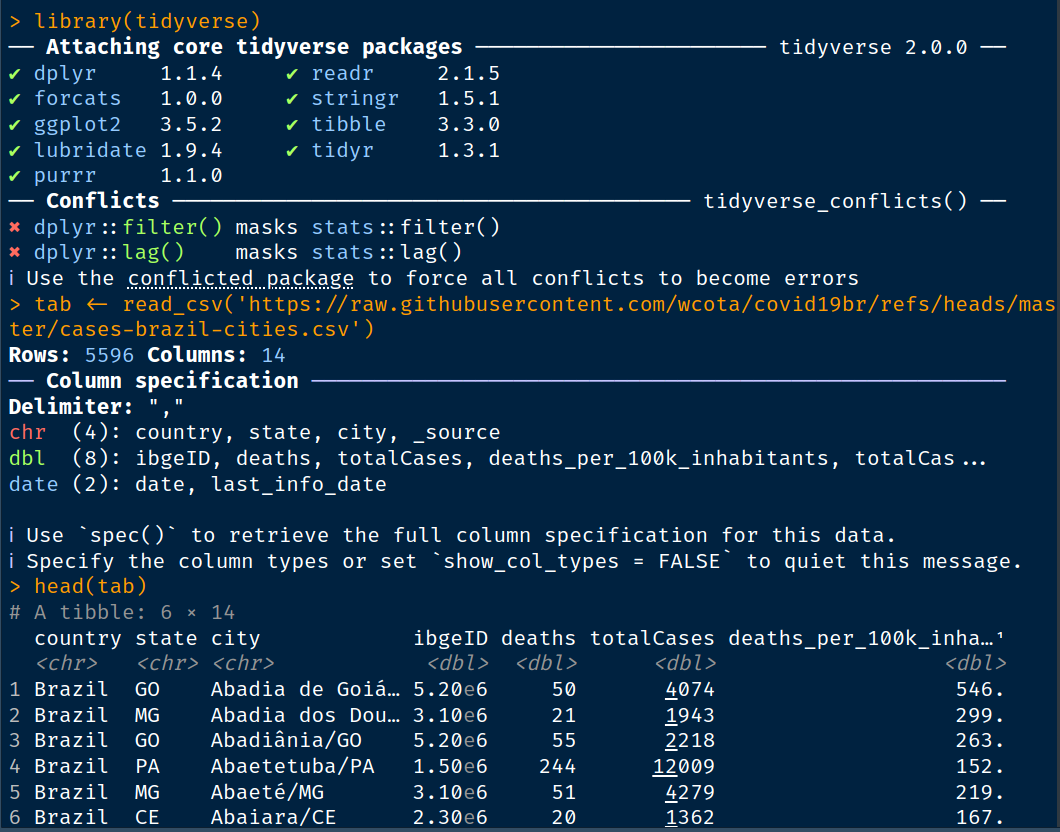
Tendo o endereço da URL, em apenas um comando podemos importar o conteúdo de uma tabela ou dados localizados numa página.
Essa página pode ser num local web usando o protocolo https, http ou, por exemplo, ftp.
paises <- read_csv('http://157.86.198.20/dados/paises.csv')Mas nem sempre é tão simples assim. A segurança na web evoluiu significativamente, e os navegadores modernos e até mesmo as ferramentas que fazem requisições HTTP estão se tornando cada vez mais rigorosas na validação de certificados SSL/TLS.
Vamos baixar uma lista de preços de medicamentos do site da ANVISA:
url <- "https://dados.anvisa.gov.br/dados/TA_PRECOS_MEDICAMENTOS.csv"
read_csv(url)
Ainda é possível acessar a tabela, mas vamos precisar de um pacote chamado httr2, usado para “raspagem” (scrapper) de dados da web. Nesse pacote podemos dizer para que a autenticação seja ignorada desativando as opções (ssl_verifypeer e ssl_verifyhost). Assim, nem a conexão e nem o site serão validados.
library(httr2)
req <- request(url) |>
req_options(ssl_verifypeer = 0) |>
req_options(ssl_verifyhost = 0)o comando acima montou uma requisição “req” que vai ser executada a seguir pela função req_perform(). Somente o dado será acessado.
A função resp_status() vai nos retornar o código web resultante da operação. Caso seja 200, a operação foi realizada com sucesso. Caso a página ou a URL esteja mal formatada, teremos como resultado o código 404, também conhecido como “Página Não Encontrada”.
resposta <- req_perform(req)
resp_status(resposta) ## ou resposta$status_code
# [1] 200Recebemos o código 200, indicando que a função foi bem sucedida, mas não termina aqui ainda. É necessário extrair o dado do objeto resposta para poder importá-lo usando uma função como read_csv(). Nesse caso vamos usar read_delim().
A função resp_body_raw() é a que vai extrair os dados do objeto resposta e passar a função que vai realizar a importação. Vamos informar a função read_delim() que o delimitador é “;” e também que o code_page usados para a acentuação é o Latin-1 (o mesmo que ISO-8859-1 / Windows-1252), usado, em geral, pelo Windows. Já o Linux e o MAC utilizam UTF-8 . Assim, se o seu computador roda Linux, é preciso informar isso. Caso você use Windows, não é necessário, mas também não retorna erro se usar.
anvisa <- read_delim(file=resp_body_raw(resposta), delim = ';',
locale=locale(encoding='latin1'))
anvisa
Como podem ver, obtivemos 53436 linhas e 16 colunas.
Podemos agora perguntar, por exemplo, quantos medicamentos estão registados que usam acido acetilsalicílico nesta base.
anvisa |>
filter(str_detect(DS_SUBSTANCIA, 'acetilsalicílico')) |>
nrow()
# [1] 281Não se preocupe que vamos ver em maiores detalhes essas funções acima nas próximas aulas.
3.2.3 Acessando o feed de notícias RSS do Ministério da Saúde
Vamos acessar o RSS que é o serviço de notícias do MS. O formato dos dados está em XML.
Formatos XML e JSON.
library(xml2)
# URL do feed RSS
rss_url <- "https://www.gov.br/aids/pt-br/assuntos/noticias/site-feed/RSS"# Leia o conteúdo do XML da URL
xml_data <- read_xml(rss_url)# Defina os namespaces usados no arquivo XML
namespaces <- c(
rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#",
d1 = "http://purl.org/rss/1.0/"
)# Encontre todos os nós <item> usando o namespace padrão
items <- xml_find_all(xml_data, "//d1:item", ns = namespaces)# Extraia os títulos de cada <item>
# O título está na tag 'title'
titulo <- xml_text(xml_find_all(items, "d1:title", ns = namespaces))# Extraia os links de cada <item>
# O link da notícia está na tag 'link'
links <- xml_text(xml_find_all(items, "d1:link", ns = namespaces))# o mesmo para o corpo
corpo <- xml_text(xml_find_all(items, "d1:description", ns = namespaces))# Crie um data frame para organizar as informações
noticias_df <- data.frame(
Titulo = titulo,
Corpo = corpo,
Link = links,
stringsAsFactors = FALSE
)print(noticias_df)3.2.4 Usando uma API para acessar Dados
O que é um API?
Uma Application Programming Interface (API), em português, Interface de Programação de Aplicações, é um conjunto de definições, protocolos e ferramentas para a criação de software e acesso a dados. Pense nela como um meio que permite a comunicação entre diferentes programas, ou mesmo entre um software e um hardware. As APIs são amplamente utilizadas no desenvolvimento de software para integrar sistemas e funcionalidades.
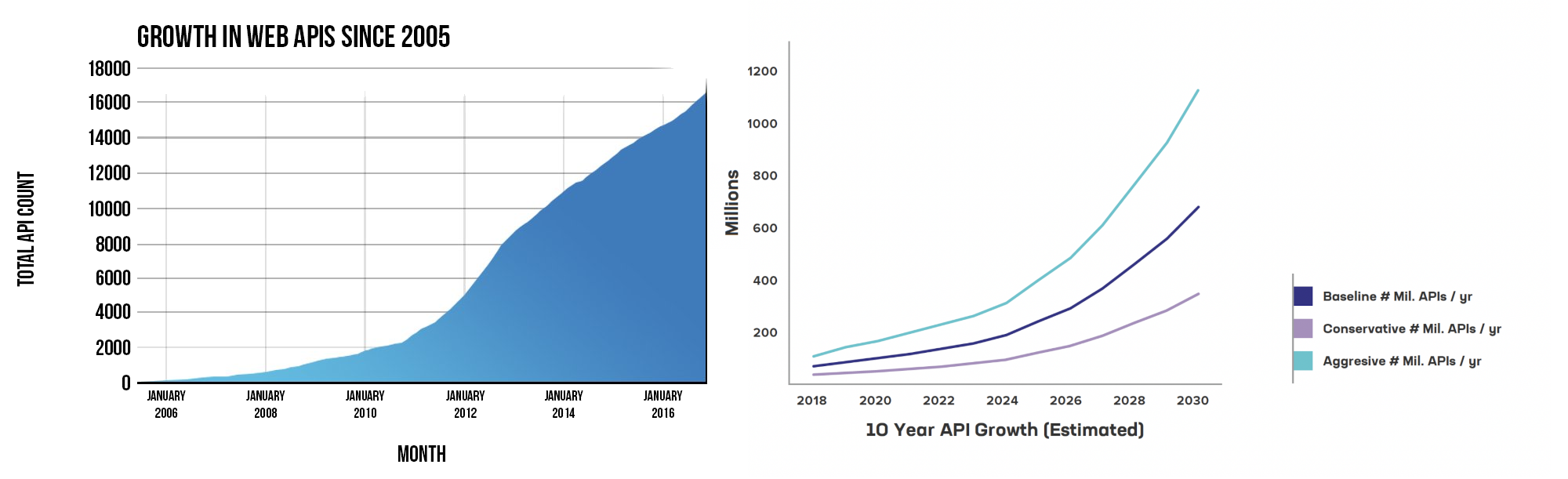
Neste curso, vamos nos concentrar no uso de APIs Web, também conhecidas como Web Services ou Web APIs. Como você pode ver no gráfico abaixo, o uso delas tem crescido significativamente, impulsionado pela popularização de repositórios de dados e pela crescente adoção de políticas de dados abertos por governos e instituições.
Para entendermos melhor como funciona uma API, imagine que você é o cliente (software) e vai a um restaurante, escolhe um prato (dados) que consta de um menu (lista de dados disponíveis) faz o pedido ao garçon (API) que leva o seu pedido a cozinha (servidor) onde o chefe (SGBD) vai preparar o seu prato. Uma vez pronto o seu prato é levado a você pelo garçon (API). Em alguns casos o menu pode deixar você customizar alguns aspetos do prato(dado), por exemplo, o ponto do filé, que deve ser especificado ao garçon (API) e preparado pelo chefe dentro de parâmetros pre estabelecidos.
3.2.5 API do INFODENGUE
O InfoDengue é um sistema de alerta para arboviroses baseado em dados híbridos gerados por meio da análise integrada de dados minerados a partir da web social e de dados climáticos e epidemiológicos.
Em 2021, o sistema ganhou amplitude nacional com o apoio do Ministério da Saúde realizando análises em nível estadual. Com isso, mais secretarias passaram a receber semanalmente os boletins do InfoDengue. Implementado em 2015, o sistema foi desenvolvido por pesquisadores do Programa de Computação Científica (Fundação Oswaldo Cruz, RJ) e da Escola de Matemática Aplicada (Fundação Getúlio Vargas) com a forte colaboração da Secretaria Municipal de Saúde do Rio de Janeiro
As tabelas geradas pelo Infodengue contem dados agregados por semana provenientes de diferentes fontes. Elas podem ser consultadas via formulário, ou diretamente do R, por meio de uma consulta à API.
Essa funcionalidade está disponível por meio da URL:
https://info.dengue.mat.br/api/alertcity?PARAMETROS_DA_CONSULTAOnde PARAMETROS_DA_CONSULTA deve conter os parâmetros:
geocode: código IBGE da cidade
disease: tipo de doença a ser consultado (dengue|chikungunya|zika)
format: formato de saída dos dados (str:json|csv)
ew_start: semana epidemiológica de início da consulta (int:1-53)
ew_end: semana epidemiológica de término da consulta (int:1-53)
ey_start: ano de início da consulta (int:0-9999)
ey_end: ano de término da consulta (int:0-9999)ATENÇÃO Todos os parâmetros acima mencionados são obrigatórios para a consulta.
url <- "https://info.dengue.mat.br/api/alertcity?"
geocode <- 4108304
disease <- "dengue"
format <- "csv"
ew_start <- 1
ew_end <- 52
ey_start <- 2015
ey_end <- 2025Em seguida precisamos concatenar a string de consulta a API nossa URL a cada um dos parâmetros separados por &
cons <- paste0(url,"geocode=",geocode,"&disease=",disease,"&format=",
format,"&ew_start=",ew_start,"&ew_end=",ew_end,"&ey_start=",ey_start,
"&ey_end=",ey_end)Formando a seguinte URL que fará a consulta ao site do infodengue:
Executando o código abaixo vamos receber o resultado da nossa consulta.
dengue_foz <- read_csv(cons)
nrow(dengue_foz)
glimpse(dengue_foz)3.2.6 API Open-Meteor
A API do Open-Meteo é uma interface de programação de aplicativos que oferece dados de previsão do tempo e climáticos de forma gratuita e com código aberto para uso não comercial e para desenvolvedores e não requer nem cadastro e nem chave para poder acessar.
meteor <- 'https://api.open-meteo.com/v1/forecast?latitude=-22.875&longitude=-43.25&timezone=America/Sao_Paulo,¤t=temperature_2m,relative_humidity_2m,wind_speed_10m&hourly=temperature_2m,relative_humidity_2m,wind_speed_10m'
previsao <- jsonlite::read_json(meteor,simplifyVector = T)
previsao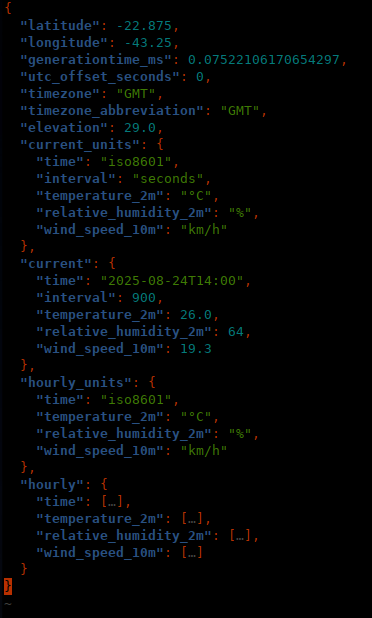
3.2.7 Importando diretamente do DATASUS
O datasus além dos conhecidos serviços disponibilizados pela internet também, há muitos anos, possui um servidor FTP de onde podemos descarregar diretamente os dados.
Podemos usar funções do R para fazer o download de um arquivo usando o protocolo FTP por exemplo:
download.file("ftp://ftp.datasus.gov.br/territorio/tabelas/04-base_territorial_abr25.zip","base_terr.zip")Vamos agora “descompactar” o arquivo ZIP. Em primeiro lugar vamos selecionar um diretório temporário que está sendo usado usando pelo R no seu sistema operacional.
loc <- tempdir()
locEm seguida vamos mandar extrair o conteúdo do ZIP nesse diretório temporário e usar o dir desse local para verificar se o conteúdo foi expandido.
unzip("base_terr.zip",exdir=loc)
dir(loc)a partir dai você poderia importar um ou mais dos arquivos que foram expandidos.
arq <- paste0(loc,"/","tb_uf.csv")
tb_uf <- read_csv2(arq,locale = locale(encoding = 'latin1'))3.2.7.1 Exemplo: Importando SINASC do Acre diretamente do DATASUS
até aqui você já viu todos os elementos necessários para fazer a importação de dados direto do FTP do DATASUS, o que precisamos é um workflow, ou seja, um plano, para fazer a importação.
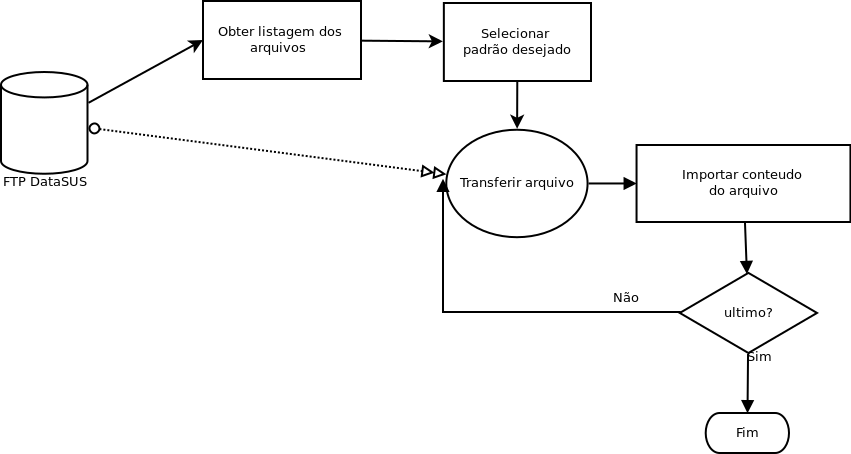
em primeiro lugar vamos usar o pacote RCurl que permite acesso a paginas http , https, ftp etc…
library(RCurl)
url <- 'ftp://ftp.datasus.gov.br/dissemin/publicos/SINASC/NOV/DNRES/'
lista <- getURL(url)vamos inspecionar o objeto lista. como vocês podem observar esse arquivo precisa ainda ser transformado para ser usado.
lista <- str_split(lista,'\n')após pedirmos ao R para inserir uma quebra apos o caractere ‘***’ agora fica mais fácil de entender a listagem que obtivemos!
vamos selecionar como UF o Acre pois o tamanho dos arquivos é pequeno e a rede da ENSP em geral não é rápida.
l2 <- str_extract(lista[[1]],'(DNAC\\d+.[dbc|DBC]{3})')## DN do ACREAqui vamos fazer um parêntesis para falar de um recurso extremamente poderoso, as expressões regulares conhecidas por REGEX
Agora que vocês já aprenderam um pouco sobre as REGEX vamos selecionar as linhas que possuem as DN do ACRE
de uma maneira simples selecionamos todas que possuem o padrão DNAC no nome seguido de um ou mais numeros (\d+) e terminado em .dbc ou .DBC.
Onde não houve match a função retorna NA, assim vamos nos livra deles!
l3 <- as.vector(na.exclude(l2))Verifique o objeto l3 para se certificar que tenhamos somente um vetor de caracteres com o nome dos arquivos! Aqui temos 27 nomes de arquivos , vamos tentar trazer todos.
Como fazer isso?
Vamos precisar criar uma nova função que possa fazer o download dos arquivos DBC e posteriormente importá-los e finalmente juntar todos. Existem diversas maneiras de se fazer isso, mas vamos usar filosofia do tideverse executando a função map do pacote purr.
le_dbc <- function(arq) {
if(!require(read.dbc)) stop("o pacote read.dbc deve estar instalado") # verifica se existe o pacote e carrega
origem <- paste0(url,arq)
destino <- paste0( tempdir(),'/temp.dbc')
download.file(origem,destino,mode="wb")
temp <- read.dbc(destino,as.is=T) |>
tibble()
file.remove(destino)
return(temp)
}Vamos testar nossa função lendo apenas um arquivo, por exemplo o DNAC2020.dbc que está na posição 25 do vetor l3.
teste <- le_dbc(l3[25])
testeSe tudo estiver certo você vai receber um objeto assim 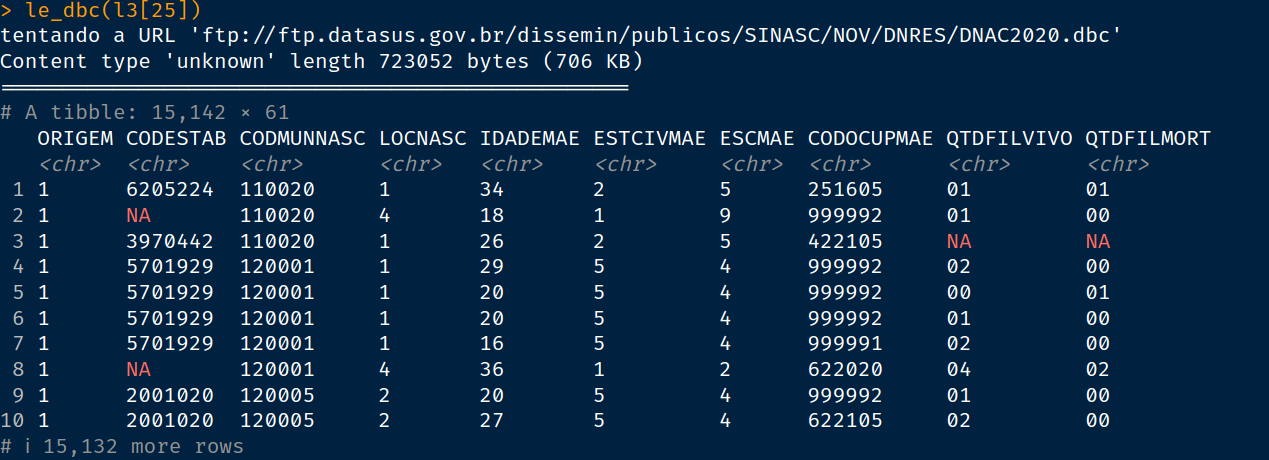
Apesar da função ter retornado um tibble podemos notar a necessidade de fazer pequenos ajustes para que ela nos retorne um conjunto de dados melhor para ser trabalhado. Os principais pontos são:
todas as variáveis retornam como texto, transformar em numéricas, datas e fatores conforme o caso.
nome das variáveis em maiúsculas, usar a função clean_names() do pacote janitor.
Criar variáveis novas com código de município de 6 caracteres para município de residência e de notificação
remover variáveis desnecessárias e com baixo grau de completude
Vamos utilizar o pacote naniar que tem funções que ajudam a sumarizar, visualizar e manipular dados falantes (missing data) .
As funções miss_var_summary e gg_miss_var() vão nos mostrar quais variáveis tem maior grau de dados faltantes.
naniar::miss_var_summary(teste)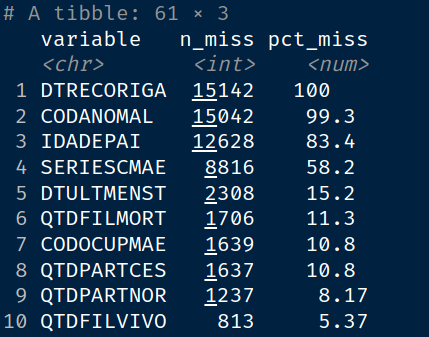
naniar::gg_miss_var(teste,show_pct = T)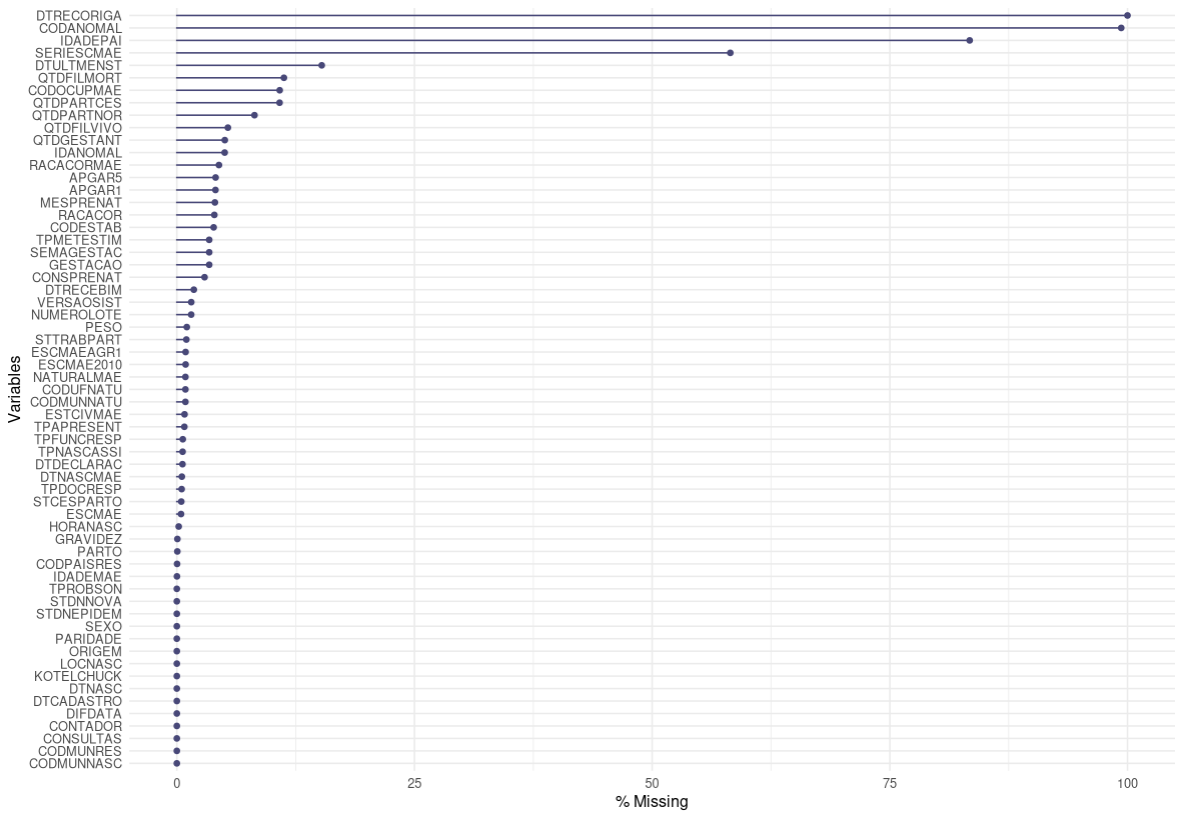
Como podemos observar as variáveis DTRECORIGA, CODANOMAL e IDADEPAI todas têm alto percentual de NAs . A coluna SERIESCMAEparece em quarto com 58% de dados faltantes baseado nessa amostra das DN do Acre de 2020.
le_dbc <- function(arq) {
if(!require(read.dbc)) stop("o pacote read.dbc deve estar instalado") # verifica se existe
remover <- c('CODANOMAL','DTRECORIGA','SERIESCMAE','IDADEPAI') ## Vars a remover
origem <- paste0(url,arq)
destino <- paste0( tempdir(),'/temp.dbc')
download.file(origem,destino,mode="wb")
temp <- read.dbc(destino,as.is=T) |>
tibble() |>
select(!any_of(remover)) |>
janitor::clean_names() |>
mutate(peso = as.numeric(peso),
idademae = as.numeric(idademae),
dtnasc = dmy(dtnasc),
codmunres6 = str_sub(codmunres,1,6),
codmun6 = str_sub(codmunnasc,1,6))
file.remove(destino)
return(temp)
}Uma vez implementada a nova função atendendo a todo o itens podemos executá-la para todo o nosso conjunto de dados usando a função map do pacote purrr.
Na verdade, vamos usar a função map_df() que agrega os resultados numa estrutura de dados tipo data.frame ou tibble.
sinasc_ac <- l3 |> map_df(le_dbc)Essa função, na minha máquina, demorou 19,5 segundos e retorno um tibble com 433.265 e um tamanho em memória de 233.7 Mb contendo todos os Nascidos vivos do AC disponíveis no FTP datasus
Vamos ver como estamos em termos de completude
naniar::miss_var_summary(sinasc_ac)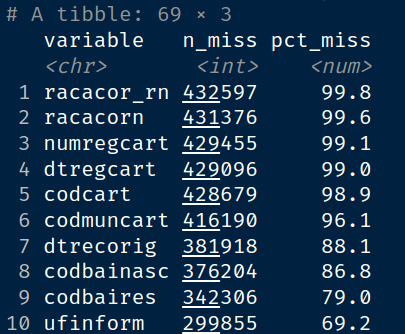
naniar::gg_miss_var(sinasc_ac,show_pct = T)Como se pode observar ainda há muitas variáveis com alta taxa de dados faltantes. Que tal modificar mais uma vez sua função de leitura e remover também essas?
Observe que o banco passou de 22 colunas em 1996 para 59 em 2022 (ultimo dado disponível em 2025) !
Parece que o seu trabalho não terminou!
3.2.8 Lendo planilhas com readxl

O readxl é um pacote que permite ler arquivos de Excel para o R. Ele faz parte do tidyverse, entretanto, precisa ser chamado individualmente com library(readxl). Para saber mais sobre o readxl, clique AQUI.
As principais funções do readxl são:
read_excel(): lê uma planilha do Excel (.xls ou .xlsx)excel_sheets(): lista os nomes das abas do arquivo Excel
Os principais parâmetros da read_excel() são:
| Parâmetro | O que faz | Exemplo |
|---|---|---|
sheet |
Define qual aba será lida (pelo nome ou posição) | read_excel("dados.xlsx", sheet = "Dados 2024") |
range |
Lê apenas um intervalo específico da planilha (ex: "B2:D10") |
read_excel("dados.xlsx", range = "B2:D10") |
skip |
Pula um número definido de linhas no início do arquivo | read_excel("dados.xlsx", skip = 2) |
na |
Define quais strings devem ser interpretadas como valores ausentes (NA) | read_excel("dados.xlsx", na = c("", "NA", "-")) |
guess_max |
Número de linhas usadas para a função tentar identificar automaticamente o tipo das colunas | read_excel("dados.xlsx", guess_max = 1000) |
col_names |
Indica se a primeira linha deve ser usada como nome das colunas | read_excel("dados.xlsx", col_names = FALSE) |
3.2.8.1 Exemplo com a PNAD contínua
Muitas vezes precisamos trabalhar com dados armazenados em planilhas de Excel. Veja abaixo, por exemplo, a planilha da PNAD contínua, do IBGE:
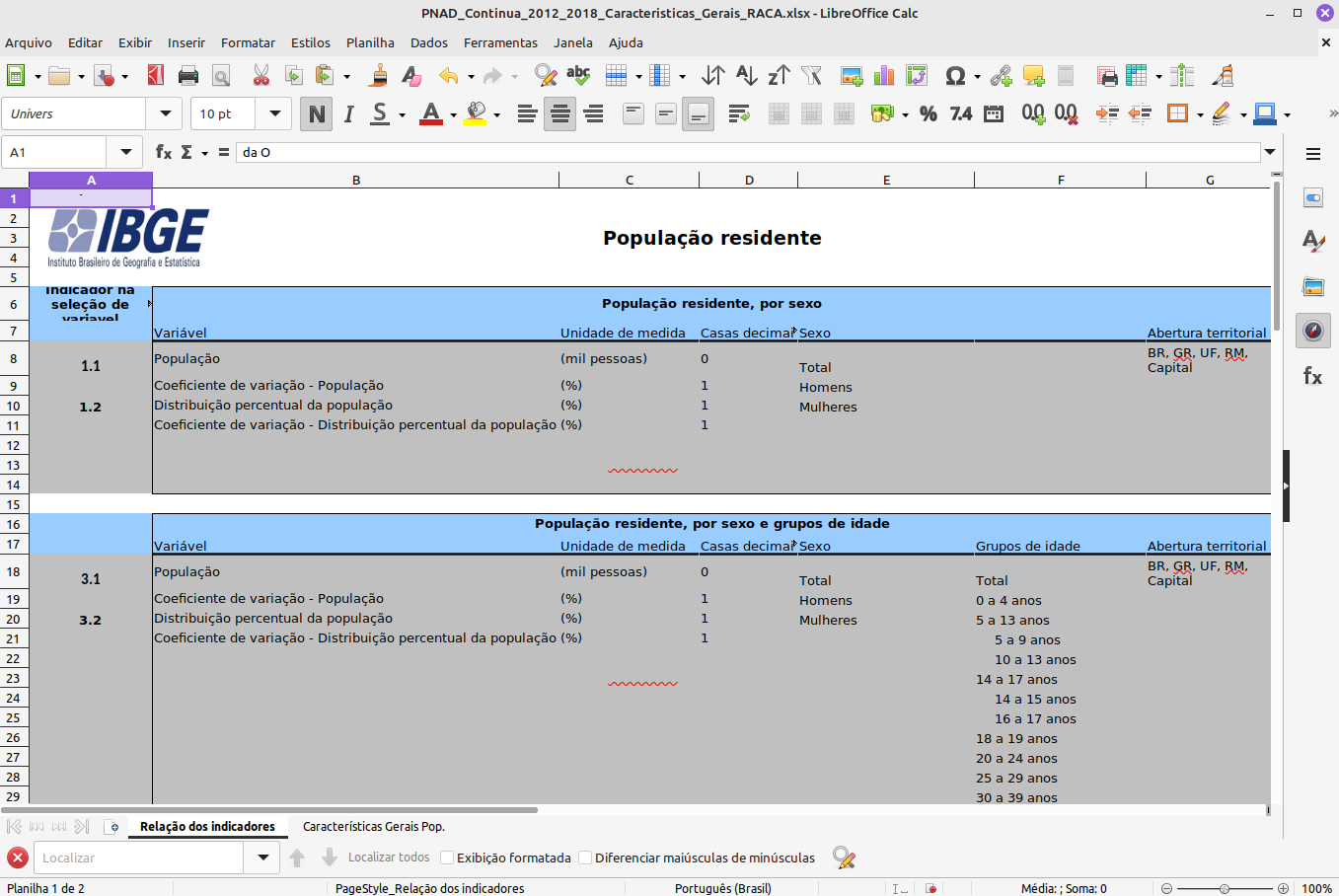
Perceba que existem duas planilhas. A primeira tem a descrição das variáveis. Vamos ver a segunda:
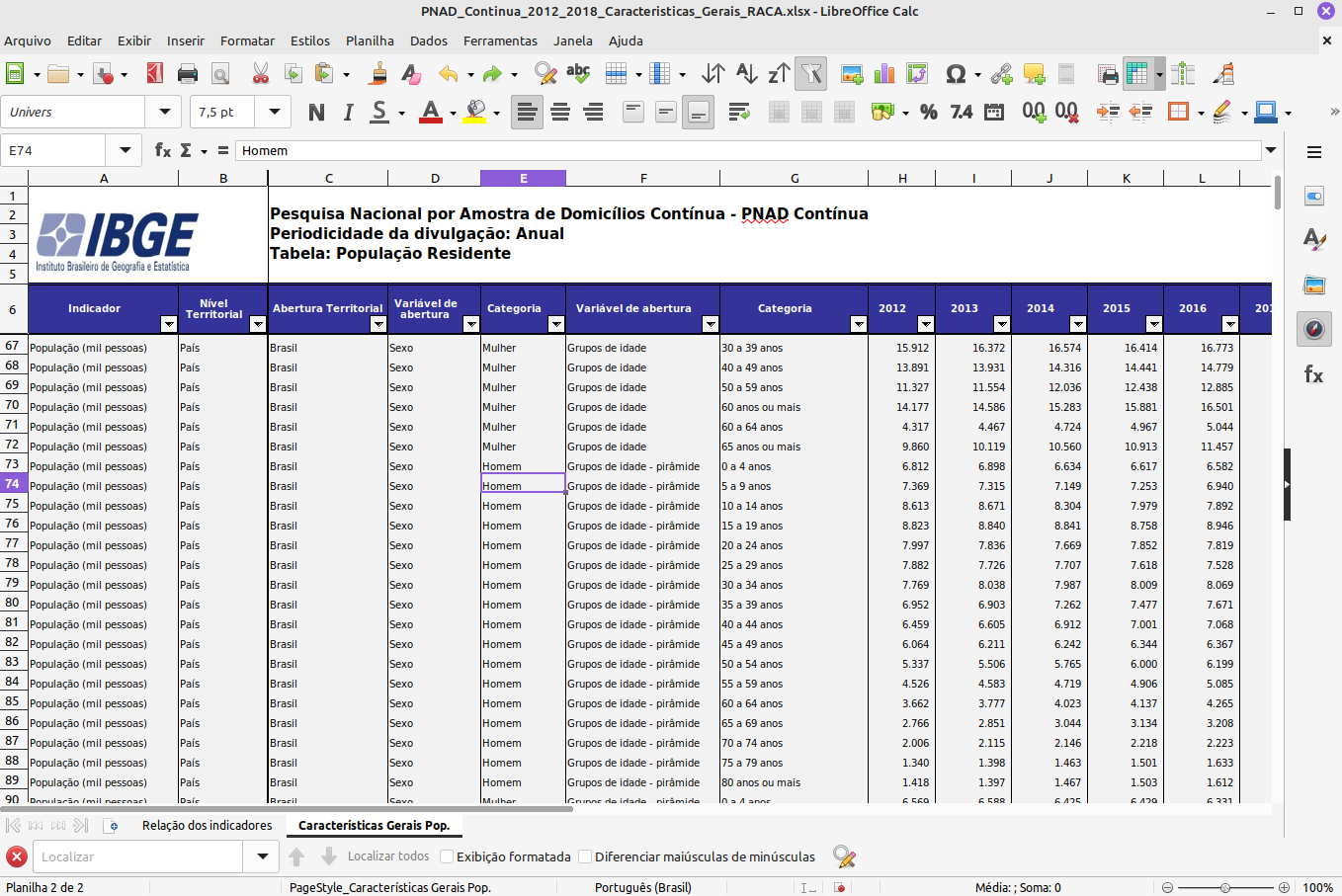
A segunda tem os dados.
Que tipo de problemas você pode ter ao tentar importar esta planilha para o R?
Vamos tentar com o readxl. Precisamos primeiro carregar o pacote. Vamos baixar os dados da PNAD e ler com read_excel.
Que parâmetros precisamos usar?
library(readxl)
url <- "https://github.com/laispfreitas/curso_CD1/raw/refs/heads/main/PNAD_Continua_2012_2018_Caracteristicas_Gerais_RACA.xlsx"
download.file(url, destfile = "pnad.xlsx", mode = "wb")
pnad <- read_excel("pnad.xlsx",
sheet = 2,
skip = 5)
New names:
• `Variável de abertura` -> `Variável de abertura...4`
• `Categoria` -> `Categoria...5`
• `Variável de abertura` -> `Variável de abertura...6`
• `Categoria` -> `Categoria...7`Repare que recebemos um aviso que algumas variáveis foram renomeadas. Isto porque a planilha original possuía várias colunas com o mesmo nome, o que não é como dados devem ser armazenados! Vamos verificar essa tabela:
pnad
# A tibble: 42,120 × 14
Indicador `Nível Territorial` `Abertura Territorial` Variável de abertura…¹ Categoria...5
<chr> <chr> <chr> <chr> <chr>
1 População (mil p… País Brasil Sexo Total
2 População (mil p… País Brasil Sexo Homem
3 População (mil p… País Brasil Sexo Mulher
4 População (mil p… País Brasil Sexo Total
5 População (mil p… País Brasil Sexo Total
6 População (mil p… País Brasil Sexo Total
7 População (mil p… País Brasil Sexo Total
8 População (mil p… País Brasil Sexo Homem
9 População (mil p… País Brasil Sexo Homem
10 População (mil p… País Brasil Sexo Homem
# ℹ 42,110 more rows
# ℹ abbreviated name: ¹`Variável de abertura...4`
# ℹ 9 more variables: `Variável de abertura...6` <chr>, Categoria...7 <chr>, `2012` <dbl>,
# `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>, `2018` <dbl>
# ℹ Use `print(n = ...)` to see more rowsParece que a planilha foi importada corretamente. Agora, há um longo caminho para transformar esses dados em dados tidy…